Các công cụ tốt nhất để tăng cường âm thanh và chất lượng âm thanh phòng thu năm 2026

Năm 2026, đạt được âm thanh chất lượng chuyên nghiệp dễ tiếp cận hơn bao giờ hết. Cho dù bạn đang ghi podcast từ nhà, làm sạch phỏng vấn thực địa, hoặc đánh bóng lồng tiếng, công cụ tăng cường đúng có thể biến đổi các bản ghi tầm thường thành âm thanh cấp phòng thu.
Thách thức không phải là tìm các công cụ hoạt động, mà là chọn cái phù hợp với quy trình làm việc, ngân sách và kỳ vọng chất lượng của bạn.
Hướng dẫn này khảo sát các công cụ tăng cường âm thanh hàng đầu có sẵn ngày nay. Mỗi công cụ có cách tiếp cận khác nhau để cải thiện chất lượng âm thanh. Một số sử dụng tái tổng hợp giọng nói AI tích cực để xây dựng lại âm thanh từ đầu. Những công cụ khác tập trung vào xử lý bảo thủ bảo tồn đặc tính gốc của giọng nói của bạn.
Một số xuất sắc trong việc loại bỏ tiếng ồn nền, trong khi những công cụ khác chuyên về cân bằng mức độ, master, hoặc loại bỏ tics lời nói.
Công cụ tốt nhất cho bạn phụ thuộc vào những gì bạn đang làm việc và những gì bạn cần đạt được. Dưới đây, chúng ta sẽ khám phá điểm mạnh, hạn chế và trường hợp sử dụng lý tưởng của mỗi công cụ. Ở cuối, bạn sẽ tìm thấy các khuyến nghị nhanh dựa trên các kịch bản và ý định phổ biến.
AudioEnhancer.com
AudioEnhancer.com là một nền tảng tăng cường âm thanh và video được hỗ trợ bởi AI được thiết kế để làm sạch, cân bằng và chuyên nghiệp hóa âm thanh nhanh chóng và trực tiếp. Trọng tâm là một luồng đơn giản: tải lên, xử lý và tải xuống, không có tính năng không cần thiết hoặc độ phức tạp kỹ thuật.
Những gì nó làm tốt: Tôi phát hiện ra nó xử lý tiếng ồn nền nghiêm trọng, phản xạ dữ dội, clipping, phụ âm bật và mất cân bằng âm lượng lớn rất tốt, miễn là giọng nói gốc trung thực. Nó hoạt động nhất quán với các bản ghi được thực hiện sử dụng:
- Micro chuyên dụng
- Máy ghi âm di động
- Micro điện thoại
Xử lý ưu tiên bảo tồn tông màu con người, tránh giọng nói robot, âm thanh kim loại, hoặc các hiện tượng không mong muốn kỹ thuật số phổ biến trong các cách tiếp cận tái tổng hợp tích cực.
Nó đặc biệt hiệu quả trong nội dung với nhiều người nói, đảm bảo mức độ nhất quán và dễ hiểu trong suốt toàn bộ bản ghi.
Trọng tâm độc quyền vào đầu vào → xử lý → tải xuống làm cho công cụ lý tưởng nếu bạn cần kết quả ngay lập tức, không có bảng điều khiển phức tạp hoặc quy trình làm việc dài.
Nó hỗ trợ cả tệp âm thanh và video, làm cho nó hữu ích cho nội dung dành cho YouTube, mạng xã hội, phỏng vấn video, hoặc UGC.
Bảng điều khiển tối giản và dễ sử dụng, được thiết kế cho người dùng muốn giải quyết một vấn đề cụ thể mà không có đường cong học tập.
Hành vi có thể dự đoán và nhất quán làm cho công cụ phù hợp cho việc sử dụng lặp lại bởi người sáng tạo và chuyên gia coi trọng sự ổn định và tự nhiên.
Nơi nó gặp khó khăn
-
AudioEnhancer.com không phải là tùy chọn tốt nhất để tái tạo các giọng nói bị suy giảm cao hoặc bị nén. Ví dụ bao gồm bản ghi cuộc gọi điện thoại hoặc âm thanh với mất thông tin phổ nghiêm trọng.
-
Công cụ hướng đến kết quả và không cung cấp điều chỉnh thủ công chi tiết các tham số. Điều này có thể hạn chế người dùng kỹ thuật âm thanh nâng cao.
-
Nó tập trung độc quyền vào cải thiện âm thanh. Nó không bao gồm chỉnh sửa, phiên âm, hoặc tính năng tái sử dụng nội dung, có thể yêu cầu các công cụ bổ sung trong các quy trình làm việc khác.
Tốt nhất cho
AudioEnhancer.com là một công cụ cực kỳ đáng tin cậy để làm sạch và chuyên nghiệp hóa âm thanh và video trong điều kiện ghi âm thực tế.
Nó đặc biệt được khuyến nghị khi:
- Điều kiện ghi âm không lý tưởng (tiếng vang, tiếng ồn, clipping)
- Mục tiêu là có được âm thanh phòng thu nhanh chóng
- Ưu tiên là sự đơn giản, khả năng dự đoán và tự nhiên
Nó không phải là công cụ cho "phép màu nhân tạo", mà là một bộ làm sạch âm thanh mạnh mẽ và ổn định, được thiết kế cho người sáng tạo nội dung và chuyên gia cần kết quả nhất quán và tự nhiên mà không có ma sát kỹ thuật.
Adobe Podcast Enhance Speech
Adobe Podcast Enhance Speech (trước đây là Project Shasta) là một công cụ dựa trên trình duyệt sử dụng các mô hình học sâu để biến đổi bản ghi giọng nói chất lượng thấp thành âm thanh nghe như thể nó được chụp trong một phòng thu chuyên nghiệp.
Công nghệ dựa vào tái tổng hợp giọng nói, nơi AI không chỉ lọc tiếng ồn mà tạo ra một giọng nói mới bắt chước tông màu của người nói gốc.
Những gì nó làm tốt: Tôi phát hiện ra nó thực sự ấn tượng để khôi phục âm thanh được ghi trong môi trường không thể. Điều này bao gồm:
- Phòng hội nghị ồn ào
- Khách sạn với Wi-Fi không ổn định
- Đường phố bận rộn với giao thông nặng
Nó xuất sắc trong việc loại bỏ các loại tiếng ồn cụ thể bao gồm gió, quạt công nghiệp, máy hút bụi, máy móc xây dựng và nhạc nền. Công cụ có thể tách người nói chính ngay cả khi các giọng nói khác chồng chéo.
Nó đáng ngạc nhiên hiệu quả trong việc sửa chữa âm thanh bị clip đã bị quá tải tăng micro. Giao diện đơn giản drag-and-drop với đường cong học tập bằng không.
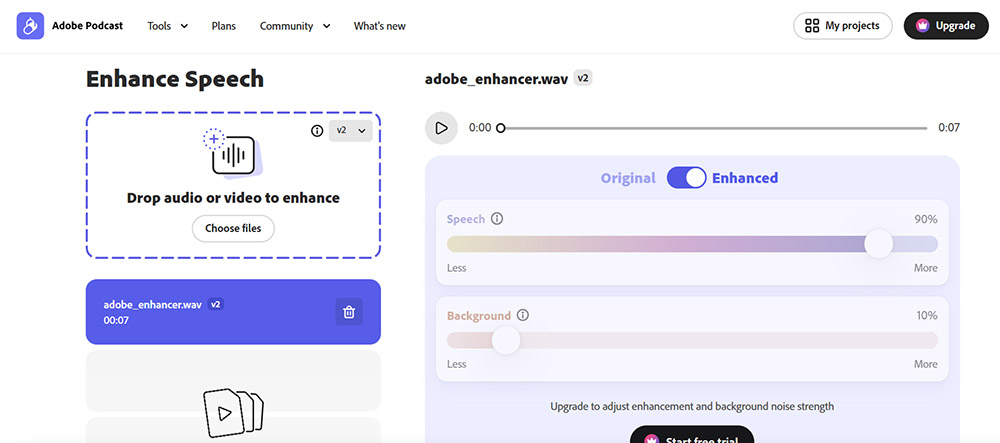
Nó hoạt động đặc biệt tốt với bản ghi AirPods do khoảng cách không đổi giữa micro và miệng. Nó có thể làm cho micro 20€ nghe như micro 100€.
Nơi nó gặp khó khăn
-
Cùng công nghệ tái tổng hợp cho phép phép màu có thể thất bại, làm cho giọng nói nghe kim loại, robot, hoặc bị nén kỳ lạ. Điều này xảy ra đặc biệt trong phiên bản V2 hoặc khi tiếng ồn gốc quá dày đặc.
-
Trong điều kiện tiếng ồn cực đoan, AI có thể phát minh âm vị hoặc từ người nói chưa bao giờ nói. Nó thậm chí có thể trộn các giọng nói ngẫu nhiên vào tệp cuối cùng.
-
Phiên bản web vượt trội hơn nhiều so với tích hợp Premiere Pro, bị giới hạn để tránh chặn phần cứng người dùng. Điều này buộc nhiều chuyên gia vào quy trình làm việc round-trip liên tục.
-
Nó không phù hợp cho nhạc hoặc cảnh quan âm thanh phức tạp nơi bạn muốn bảo tồn không khí. Công cụ cố gắng làm sạch mọi thứ không phải là giọng nói con người, có thể phá hủy ý định nghệ thuật.
-
Phiên bản miễn phí không cung cấp cài đặt để điều chỉnh, để bạn phụ thuộc vào kết quả tự động.
Tốt nhất cho
-
Người sáng tạo nội dung cần cứu các bản ghi từ môi trường kém
-
Người làm podcast làm việc với thiết lập ghi âm không nhất quán
-
Bất kỳ ai cần cải thiện nhanh mà không có kiến thức kỹ thuật
Tôi phát hiện ra điểm ngọt ngào là đặt thanh trượt cường độ (có sẵn trong premium) khoảng 70-75% cho âm thanh tự nhiên nhất. Thay vào đó, xử lý trước âm thanh với giảm tiếng ồn nhẹ trước khi áp dụng công cụ tăng cường của Adobe ở 20-40% hoạt động tốt cho đánh bóng cuối cùng.
Auphonic
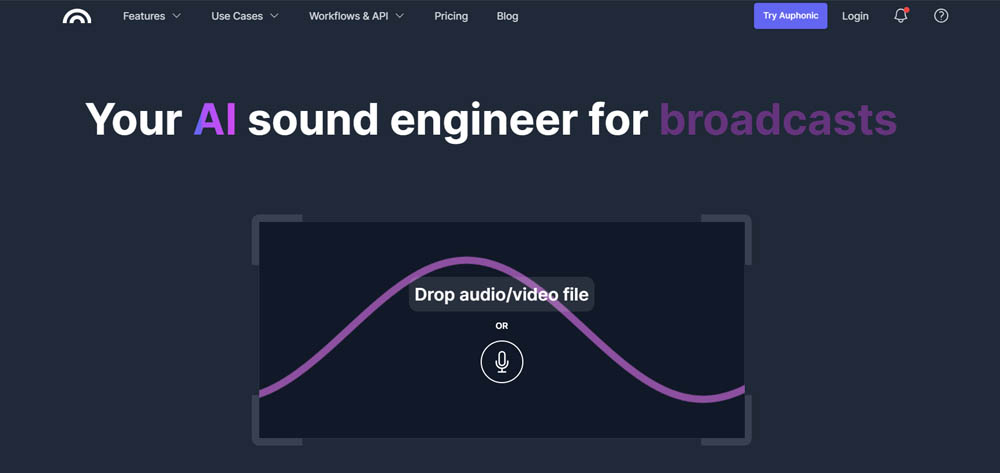
Auphonic là một dịch vụ hậu sản xuất âm thanh dựa trên đám mây hoạt động dưới triết lý "đánh bóng tự nhiên." Không giống như các công cụ như Adobe Podcast sử dụng tái tổng hợp giọng nói tích cực, Auphonic tập trung vào tối ưu hóa kỹ thuật của bản ghi gốc.
Nó được coi rộng rãi là "tiêu chuẩn vàng" cho master tự động trong số các cựu chiến binh podcast. Khi so sánh Auphonic vs Adobe, sự khác biệt trong kiểm soát kỹ thuật so với tái tổng hợp tích cực trở nên rõ ràng.
Những gì nó làm tốt: Intelligent Leveler là tính năng được ca ngợi nhất. AI phân tích tệp và tự động cân bằng mức độ giữa các người nói, nhạc và hiệu ứng âm thanh khác nhau. Điều này loại bỏ nhu cầu cho các bộ nén thủ công phức tạp.
Nó là công cụ đi đến để đảm bảo âm thanh đáp ứng tiêu chuẩn độ lớn nền tảng. Điều này bao gồm -14 LUFS cho YouTube hoặc -16 LUFS cho podcast, ngăn âm thanh nghe quá yên lặng hoặc méo.
Tính năng Crossgate được ca ngợi cao cho các bản ghi với nhiều micro trong cùng một không gian. Nó giảm đáng kể rò rỉ micro khi giọng nói của một người được chụp bởi micro của người khác.
Thuật toán loại bỏ hơi thở được coi là một trong số ít trên thị trường hoạt động đủ tốt để tiết kiệm hàng giờ chỉnh sửa thủ công. Nó cũng hiệu quả loại bỏ tiếng click miệng và im lặng khó xử.
Bandwidth Extension có thể khôi phục cuộc sống cho các bản ghi bị nghẹt hoặc độ trung thực thấp bằng cách khôi phục các tần số dường như đã mất.
Một lợi thế độc đáo là Auphonic không tính phí tín dụng bổ sung nếu bạn quyết định thay đổi cài đặt trên tệp đã xử lý và chạy sản xuất lại.
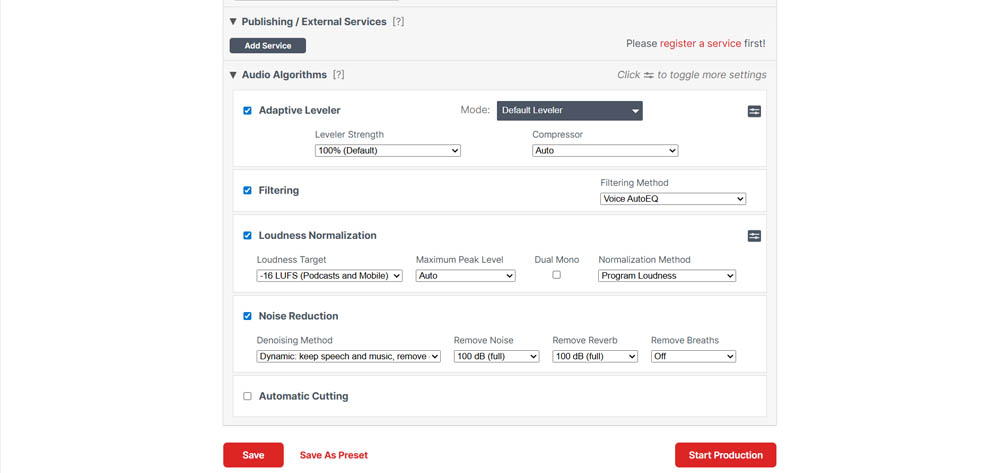
Nó cung cấp quy trình làm việc set-and-forget với hỗ trợ cho:
- Siêu dữ liệu
- Ghi chú chương trình tự động
- Chương
- Phiên âm qua Whisper bằng nhiều ngôn ngữ
Nơi nó gặp khó khăn
-
Auphonic không phải là công cụ "phép màu tái tổng hợp" như Adobe. Nếu âm thanh gốc có tiếng ồn nền hoặc phản xạ cực kỳ tích cực, Auphonic có thể không tách giọng nói tốt như các mô hình tạo mới hơn.
-
Thiết kế nền tảng web cảm thấy lỗi thời so với tiêu chuẩn hình ảnh hiện đại 2025.
-
Mặc dù nó cung cấp nhiều tham số, một số tính năng được liên kết. Ví dụ, thuật toán DeBreath đôi khi bị ràng buộc với bộ giảm tiếng ồn, ngăn điều chỉnh độc lập mức giảm hơi thở so với tiếng ồn băng thông rộng.
-
Phiên bản miễn phí (cung cấp 2 giờ mỗi tháng) thêm một jingle âm thanh nhỏ ở đầu hoặc cuối các sản phẩm đã xử lý.
-
Trong khi nó xử lý nhạc tốt trong một số cài đặt, sức mạnh chính của nó là đối thoại. Nó có thể không lý tưởng cho master nhạc thuần túy.
Tốt nhất cho
Người làm podcast muốn âm thanh chuyên nghiệp, trung thực duy trì động lực giọng nói tự nhiên mà không nghe như robot AI. Nó lý tưởng khi:
- Bản ghi gốc đã hợp lý
- Có nhiều người nói cần âm lượng nhất quán
- Người sáng tạo sản xuất tập hàng tuần và muốn chữ ký âm thanh giống hệt nhau trên tất cả nội dung
Nếu bạn thấy Adobe Podcast quá nhân tạo hoặc nhận thấy các hiện tượng không mong muốn kim loại, Auphonic cung cấp sự cân bằng hoàn hảo.
Cleanvoice AI
Cleanvoice AI là một công cụ hậu sản xuất dựa trên đám mây được phân biệt bởi trọng tâm của nó vào các vấn đề vi âm học và tics lời nói. Không giống như các công cụ chỉ giảm tiếng ồn môi trường, Cleanvoice được đào tạo đặc biệt để xác định và loại bỏ các yếu tố sinh học và sự do dự làm cho việc nghe podcast mệt mỏi.
Những gì nó làm tốt: Nó rất hiệu quả trong việc tự động phát hiện từ đệm như "um", "ah" và "like" trong hơn 20 ngôn ngữ.
Nó được mô tả là "phẫu thuật hơn" so với đối thủ như Descript trong việc loại bỏ:
- Âm thanh miệng
- Tiếng click
- Tiếng môi
- Hơi thở nặng
Một trong những điểm mạnh lớn nhất của nó là nó không thay đổi tông màu giọng nói gốc một cách tích cực như Adobe Podcast. Nó duy trì nhịp điệu tự nhiên của lời nói, chỉ loại bỏ các yếu tố phân tâm. So sánh CleanVoice vs Adobe chứng minh cách mỗi công cụ xử lý các kịch bản tiếng ồn khác nhau.
Thay vì áp dụng các thay đổi phá hủy tự động, Cleanvoice trình bày cho bạn một dòng thời gian các đề xuất. Điều này cho phép bạn chấp nhận hoặc từ chối chỉnh sửa riêng lẻ.
Nó hiệu quả xác định và loại bỏ "không khí chết" (im lặng kéo dài), cải thiện nhịp điệu nội dung mà không cần nỗ lực thủ công.
Nơi nó gặp khó khăn
-
Khi đối mặt với tiếng ồn nền đáng kể hoặc môi trường rất ồn ào, âm thanh đã xử lý có thể bắt đầu nghe "pixel hóa", "nhăn", hoặc với hiệu ứng autotune kỳ lạ.
-
Mặc dù cung cấp dịch vụ phiên âm, tôi phát hiện ra kết quả đáng thất vọng. Phần mềm miễn phí như Audacity đạt được kết quả vượt trội trong lĩnh vực cụ thể này.
-
Nó là công cụ làm sạch âm thanh, không phải trình chỉnh sửa hoàn chỉnh. Nó thiếu tính năng chỉnh sửa video mạnh mẽ hoặc khả năng xử lý thời gian thực.
-
Mô hình giá dựa trên giờ xử lý (ví dụ, 11€ cho 10 giờ) có thể trở nên đắt đỏ nếu bạn sản xuất khối lượng lớn nội dung.
-
Mặc dù nó loại bỏ tiếng ồn, nó kém hiệu quả hơn Adobe hoặc iZotope RX trong việc xử lý phản xạ trong phòng lớn. Trong một số trường hợp, tôi thích âm thanh gốc hơn kết quả "pixel hóa".
Tốt nhất cho
-
Người làm podcast với tics lời nói
-
Người sáng tạo thường xuyên do dự hoặc có âm thanh miệng nổi bật sẽ không thể chỉnh sửa thủ công trong các tập dài
-
Nếu bạn ghét âm thanh tổng hợp/robot của Adobe và thích duy trì kết cấu gốc của giọng nói của bạn. Bạn sẽ cần chấp nhận rằng tiếng ồn nền có thể không được loại bỏ hoàn toàn để đổi lấy độ trung thực lớn hơn
-
Biên tập viên muốn AI làm công việc nặng nhọc của việc tìm lỗi nhưng muốn quyết định cuối cùng về những gì được cắt qua hệ thống đề xuất
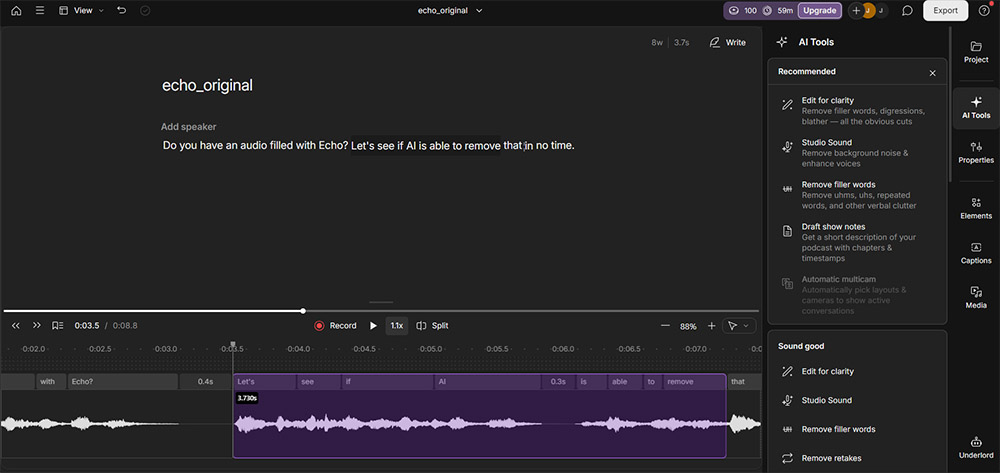
Descript Studio Sound
Descript Studio Sound không chỉ là một bộ xử lý âm thanh đơn giản, mà là một tính năng trung tâm trong hệ sinh thái chỉnh sửa tất cả trong một định nghĩa lại năng suất thông qua chỉnh sửa dựa trên văn bản.
Tôi thấy mình ấn tượng bởi hiệu quả của nó, mặc dù tôi có một số chỉ trích cụ thể về kết cấu âm thanh đã xử lý.
Những gì nó làm tốt: Lợi thế lớn nhất được trích dẫn là tích hợp Studio Sound vào quy trình làm việc nơi bạn chỉnh sửa âm thanh như thể nó là một tài liệu văn bản.
Khả năng loại bỏ tiếng ồn nền, tiếng vang và phản xạ bằng một cú nhấp, đồng thời loại bỏ từ đệm ("um" và "ah") và im lặng, được coi là giải pháp không thể đánh bại cho tốc độ sản xuất. So sánh Descript vs Adobe làm nổi bật cách khác biệt quy trình làm việc ảnh hưởng đến việc sử dụng thực tế.
Trong thử nghiệm của tôi, Descript làm tôi ngạc nhiên bằng cách biến đổi âm thanh từ "xấu thành tốt" và "tốt thành xuất sắc." Tôi sẽ đánh giá nó 8/10 cho độ rõ ràng và khả năng làm cho các bản ghi tầm thường có thể sử dụng cho nội dung chuyên nghiệp.
Công cụ có thể khôi phục âm thanh được ghi trong điều kiện tồi tệ, như qua "lon thiếc" hoặc điện thoại cũ, làm cho nó có thể nghe và sạch.
Ngoài cải thiện âm thanh thuần túy, Descript cung cấp các công cụ như Overdub (kỹ thuật nhân bản giọng nói để sửa lỗi mà không cần ghi lại) và điều chỉnh liên hệ mắt được hỗ trợ bởi AI. Những điều này bổ sung trải nghiệm tạo video và podcast.
Không giống như một số công cụ tự động, Descript cho phép điều chỉnh cường độ hiệu ứng Studio Sound qua thanh trượt. Điều này cho bạn tự do tìm sự cân bằng giữa độ sạch hoàn toàn và tự nhiên.
Nơi nó gặp khó khăn
-
Một chỉ trích lặp lại là Studio Sound có thể tạo ra âm thanh "kim loại" hoặc "robot". Điều này xảy ra đặc biệt khi thuật toán bị buộc xử lý tệp với tiếng ồn nặng hoặc khi được áp dụng ở cường độ tối đa.
-
Tôi nhận thấy AI gặp khó khăn khi xử lý giọng nơi từ ngữ hòa quyện với nhau. Điều này dẫn đến các vết cắt đột ngột, "nhảy" âm thanh, hoặc nói lắp kỹ thuật số không mong muốn.
-
Mặc dù tính năng kỹ thuật nhân bản giọng nói ấn tượng về mặt kỹ thuật, giọng nói được tạo có thể nghe không cảm xúc hoặc "chết". Điều này yêu cầu giám sát con người liên tục để tránh tông tổng hợp quá mức.
-
Không giống như các công cụ 100% đám mây (như Adobe), Descript sử dụng sức mạnh xử lý máy tính của bạn. Điều này có nghĩa là hiệu suất công cụ và tốc độ ứng dụng phụ thuộc trực tiếp vào phần cứng có sẵn của bạn.
-
Quy trình xuất và xuất bản cảm thấy kỳ lạ và đôi khi chậm, đặc biệt so với các công cụ web đơn giản.
-
Đăng ký gói chuyên nghiệp (khoảng $35 USD/tháng) là cấm đối với người sáng tạo thỉnh thoảng hoặc độc lập. Bạn có thể kết thúc tìm kiếm các lựa chọn thay thế miễn phí hoặc trả tiền cho mỗi lần sử dụng.
Tốt nhất cho
-
Nhóm sản xuất coi trọng tốc độ và đã sử dụng nền tảng cho chỉnh sửa video nhiều camera hoặc phiên âm
-
Tuy nhiên, nếu bạn đang tìm kiếm độ trung thực âm thanh tối đa hoặc làm việc với giọng không phải Mỹ, hãy lắng nghe cẩn thận kết quả. Công cụ có thể hy sinh tự nhiên để đổi lấy độ sạch hoàn toàn
-
Nó được xem như một công cụ "cho âm thanh một facelift", nhưng nếu sử dụng sai, có thể loại bỏ "trái tim" và cảm xúc từ giọng nói con người
DaVinci Resolve Voice Isolation
DaVinci Resolve Voice Isolation là một công cụ cách mạng đã mang khả năng khôi phục âm thanh chuyên nghiệp trực tiếp vào quy trình làm việc chỉnh sửa video. Tôi phát hiện ra hiệu suất của nó có thể so sánh với phần mềm chuyên dụng, đắt tiền, mặc dù có các hạn chế kỹ thuật cụ thể.
Những gì nó làm tốt: Đặc điểm ấn tượng nhất là nó là giải pháp một nút. Tôi đạt được kết quả vượt trội hoặc tương đương với iZotope RX Advanced (tiêu chuẩn ngành) với ít nỗ lực và điều chỉnh thủ công hơn nhiều.
Công cụ đã chứng minh khả năng tách giọng nói trong môi trường cực kỳ ồn ào. Ví dụ bao gồm phỏng vấn được ghi bên cạnh động cơ phản lực hoặc trong nhà hàng ồn ào với nhạc nền và tiếng va chạm đĩa.
Nó đặc biệt hiệu quả trong việc loại bỏ drone liên tục và tiếng ồn trắng, như âm thanh động cơ, làm cho âm thanh hoàn toàn có thể sử dụng.
Không giống như các công cụ như Adobe Podcast (phiên bản web), Voice Isolation được tích hợp vào phần mềm. Điều này loại bỏ nhu cầu xuất và nhập tệp để làm sạch.
Tôi phát hiện ra công cụ đưa vào ít hiện tượng không mong muốn hơn các giải pháp AI khác, duy trì giọng nói tự nhiên hơn trong khi loại bỏ tiếng ồn.
Nơi nó gặp khó khăn
-
Một trong những điểm bị chỉ trích nhất là tính năng không có sẵn trong phiên bản miễn phí của DaVinci Resolve. Nó yêu cầu mua giấy phép Studio.
-
Vì xử lý xảy ra trong thời gian thực, tôi nhận thấy âm thanh có thể "bị kẹt" hoặc nói lắp trong quá trình xem trước dòng thời gian. Điều này xảy ra đặc biệt trong các phân đoạn video nơi hiệu ứng đã được áp dụng.
-
Nếu cường độ quá cao, AI có thể không phân biệt giữa tiếng ồn và biểu hiện con người không ngôn ngữ. Điều này có thể kết thúc cắt tiếng cười, tiếng la hét, hoặc tiếng thở dài, có thể yêu cầu ADR thủ công.
-
Tôi nhận thấy công cụ đưa vào các thay đổi tông hoặc cao độ không mong muốn trong các clip rất ngắn (như bản ghi lái xe). Nó thỉnh thoảng thất bại trong việc xử lý tiếng ồn hoặc cắt âm thanh hoàn toàn.
-
Khi tôi thử nghiệm nó với người nói tiếng Tây Ban Nha, kết quả kém. Điều này gợi ý mô hình AI có thể đã được đào tạo chủ yếu với giọng nói tiếng Anh.
Tốt nhất cho
-
Biên tập viên video muốn làm sạch âm thanh chuyên nghiệp mà không rời khỏi môi trường chỉnh sửa của họ
-
Adobe Podcast Enhance vẫn hơi vượt trội ở loại bỏ tiếng ồn thuần túy, nhưng Resolve thắng cho sự tiện lợi của việc được tích hợp vào trình chỉnh sửa video
-
Trong khi RX cung cấp kiểm soát phẫu thuật (de-click, de-plosive, v.v.), Resolve tốt hơn cho tốc độ trong tách đối thoại thuần túy. Nó cảm thấy như "phép màu" cho sự đơn giản của nó
-
Plugin của Waves cung cấp hiệu suất thời gian thực tốt hơn mà không có "nấc cục" phần cứng, mặc dù tách của Resolve là hàng đầu
Krisp
Krisp được công nhận rộng rãi như người lãnh đạo không thể tranh cãi trong xử lý âm thanh thời gian thực. Nó được phân biệt từ hầu hết các công cụ khác chỉ hoạt động trong hậu sản xuất. Hiểu sự đánh đổi thời gian thực vs hậu sản xuất giúp xác định cách tiếp cận nào phù hợp với quy trình làm việc của bạn.
Nó hoạt động như một lớp giữa micro và phần mềm ghi âm hoặc hội nghị, sử dụng AI để làm sạch âm thanh trước khi nó thậm chí được ghi.
Những gì nó làm tốt: Nó xuất sắc trong việc loại bỏ ngay lập tức tiếng ồn gia đình và đô thị không thể dự đoán. Ví dụ bao gồm trẻ em cười, chó sủa, hoặc cửa đóng sầm.
Công cụ được thiết kế để có mức tiêu thụ CPU thấp, đảm bảo máy tính không mất hiệu suất trong cuộc gọi video hoặc phiên phát trực tuyến đồng thời.
Nó hoạt động với hơn 800 ứng dụng, bao gồm:
- Zoom
- Microsoft Teams
- Skype
- OBS
- DAW như Audacity
Ngoài việc làm sạch giọng nói của bạn (micro), Krisp cũng có thể làm sạch âm thanh đến từ các người tham gia khác trong cuộc gọi (loa), loại bỏ tiếng ồn nền của họ.
Nó bao gồm các công cụ tự động để tạo ghi chú cuộc họp và phiên âm không giới hạn, giúp tiết kiệm hàng giờ công việc hành chính hàng tuần.
Nó cung cấp một gói miễn phí hào phóng cung cấp 60 phút xử lý mỗi ngày. Điều này đủ cho người sáng tạo thỉnh thoảng và chuyên gia trong các cuộc họp thỉnh thoảng.
Nơi nó gặp khó khăn
-
Giá của việc loại bỏ tiếng ồn tích cực là suy giảm độ trung thực giọng nói. Âm thanh đã xử lý có thể nghe "mỏng", với tiếng vang nhẹ hoặc kết cấu "phẳng" và robot.
-
Khi tôi thử nghiệm nó trong môi trường đã yên tĩnh với micro phòng thu chất lượng cao, Krisp cố gắng "tìm tiếng ồn nơi nó không tồn tại." Điều này cuối cùng phá hủy độ rõ ràng và sự hiện diện tự nhiên của giọng nói.
-
Mặc dù nó cung cấp tính năng định vị/chuyển đổi giọng, kết quả đáng thất vọng. Chúng nghe chung chung và không tự nhiên, không nắm bắt được bản chất của giọng nói gốc.
-
Là một công cụ yêu cầu xác minh, nó có chức năng ngoại tuyến hạn chế.
-
Sự chuyển đổi từ giấy phép trọn đời sang mô hình đăng ký hàng tháng có thể ít hấp dẫn hơn cho những người không sử dụng nó hàng ngày.
Tốt nhất cho
-
Công nhân từ xa, streamer và bất kỳ ai làm công việc giọng nói thời gian thực không thể kiểm soát môi trường của họ
-
Sử dụng nó với thận trọng. Nó hợp pháp cho phát sóng trực tiếp và cuộc gọi, nhưng đối với bản ghi chuyên nghiệp yêu cầu "nirvana âm thanh", tốt hơn là ghi âm thanh "bẩn" và xử lý nó trong hậu sản xuất với các công cụ mạnh mẽ hơn như Descript hoặc Adobe. Điều này tránh giọng nói nghe quá được xử lý ngay từ nguồn
Eleven Labs Voice Isolator
Eleven Labs Voice Isolator là một lần ra mắt tương đối gần đây trong thị trường xử lý âm thanh AI. Mặc dù ít được tranh luận hơn Adobe Podcast, nó đã thu thập ý kiến mạnh mẽ và tương phản trong cộng đồng chuyên gia. So sánh ElevenLabs vs Adobe tiết lộ cách mỗi công cụ tiếp cận tách giọng nói khác nhau.
Những gì nó làm tốt: Bảo tồn tông màu là lợi thế lớn nhất. Tôi phát hiện ra Eleven Labs vượt trội so với cả hai phiên bản Adobe (Web và Premiere) trong việc duy trì tông màu giọng nói gốc.
Trong khi các công cụ khác có thể làm cho giọng nói nghe "tổng hợp" do tái tổng hợp tích cực, Eleven Labs duy trì danh tính giọng hát hữu cơ trong khi loại bỏ những gì xung quanh nó.
Nó rất hiệu quả trong việc "bóc" mọi thứ không phải là giọng nói. Nó hoàn hảo nếu bạn chỉ cần tách người nói trong các bản ghi nơi giọng nói được xác định rõ nhưng nền là hỗn loạn.
Giống như các đối thủ trực tiếp của nó, nó tập trung vào trải nghiệm đơn giản hóa, cho phép kết quả nhanh chóng mà không cần kiến thức kỹ thuật âm thanh sâu.
Nơi nó gặp khó khăn
-
Một vấn đề kỹ thuật tôi phát hiện ra là công cụ có thể gây ra các đỉnh âm thanh không mong muốn (peaking). Điều này buộc bạn phải áp dụng bộ giới hạn hoặc điều chỉnh tăng thủ công sau khi xử lý để tránh méo.
-
Không giống như các công cụ như Adobe Podcast, đôi khi "làm sạch quá mức" (loại bỏ ngay cả âm vị), bộ tách của Eleven Labs vẫn cho phép một số tiếng ồn nền trong một số điều kiện. Nó không "không khoan nhượng" trong làm sạch hoàn toàn như bạn có thể muốn.
-
Vì nó là công cụ tách, nó không cung cấp gói master hoàn chỉnh (như Auphonic) hoặc chỉnh sửa dựa trên văn bản (như Descript). Nó được xem nhiều hơn như một "mô-đun làm sạch" chuyên dụng hơn là giải pháp hậu sản xuất tích hợp.
Tốt nhất cho
-
Nếu bạn cần cứu âm thanh nơi giọng nói cần nghe thực và con người nhất có thể, không có các hiện tượng không mong muốn kim loại của Adobe
-
Tuy nhiên, bạn nên chuẩn bị đối phó với một số không nhất quán trong mức âm lượng (đỉnh) và chấp nhận rằng tách có thể không 100% im lặng trong môi trường tiếng ồn cực đoan
Riverside.fm
Riverside.fm được công nhận rộng rãi như một trong những nền tảng hàng đầu cho ghi âm từ xa chất lượng cao. Nó được phân biệt từ các công cụ tăng cường âm thanh thuần túy bằng việc là giải pháp kết hợp chụp nguồn với khả năng chỉnh sửa được hỗ trợ bởi AI.
Điều ấn tượng tôi nhất là khả năng đảm bảo âm thanh và video nghe chuyên nghiệp ngay từ thời điểm ghi âm.
Những gì nó làm tốt: Lợi thế lớn nhất là ghi âm cục bộ trên thiết bị của mỗi người tham gia. Điều này đảm bảo tệp ở độ phân giải đầy đủ (lên đến 4K trong video và WAV trong âm thanh), bất kể lỗi hoặc không ổn định internet trong phiên.
Công cụ bao gồm tính năng Magic Audio với tách được hỗ trợ bởi AI và làm sạch tự động. Tôi phát hiện ra điều này tạo ra "sự khác biệt tàn bạo" trong độ rõ ràng giọng hát, loại bỏ nhu cầu cho nhiều hậu sản xuất thủ công.
Riverside tự động biến đổi các tập dài thành "shorts" cho mạng xã hội (TikTok, Reels) và tạo ghi chú chương trình, tiêu đề và mô tả được tối ưu hóa qua AI.
Tương tự như Descript, Riverside giới thiệu tính năng AI điều chỉnh ánh mắt của người nói để họ xuất hiện luôn nhìn trực tiếp vào camera. Đây là "game changer" cho chất lượng video.
Nó cho phép chỉnh sửa âm thanh và video đơn giản bằng cách xóa câu từ phiên âm tự động. Tôi phát hiện ra phiên âm của Riverside, trong nhiều trường hợp, vượt trội so với Descript.
Dịch vụ có hỗ trợ khách hàng "top notch" và cộng đồng Facebook tích cực nơi người sáng tạo chia sẻ cải thiện và đề xuất.
Nơi nó gặp khó khăn
-
Mặc dù hiếm, tôi đã nghe báo cáo về mất mát hoàn toàn bản ghi hoặc ngắt kết nối thường xuyên trong phiên.
-
Trình chỉnh sửa văn bản cảm thấy không chính xác so với các công cụ chỉnh sửa truyền thống. Nó thất bại trong việc xử lý các chuyển tiếp rất chặt chẽ giữa các từ, có thể để lại "dấu vết" giọng hát.
-
Giống như các công cụ AI khác, mô hình dường như đã được đào tạo chủ yếu với giọng Mỹ phẳng. Điều này trình bày khó khăn với giọng dày đặc hơn (như Úc), dẫn đến các vết cắt âm thanh đột ngột.
-
Xuất tệp cuối cùng và xử lý phiên âm AI có thể chậm, đặc biệt trong các dự án thời lượng dài.
-
Với các gói bắt đầu từ $15-19 hàng tháng, chi phí cao cho những người không sản xuất nội dung chuyên nghiệp hoặc thường xuyên.
-
Mặc dù một số thấy nó trực quan, giao diện trình chỉnh sửa nội bộ cảm thấy vụng về và khó nắm vững ban đầu.
Tốt nhất cho
-
Podcast dựa trên phỏng vấn từ xa nơi chất lượng hình ảnh và âm thanh là ưu tiên
-
Tôi sử dụng nó như "trạm chụp", nhưng nhiều chuyên gia thích xuất tệp thô (WAV/MP4) sang phần mềm như DaVinci Resolve hoặc Adobe Premiere Pro để chỉnh sửa cuối cùng. Điều này hoạt động xung quanh các hạn chế trình chỉnh sửa web của Riverside
-
Tóm lại, nó là công cụ "ghi âm không thể đánh bại" nhưng với trình chỉnh sửa vẫn đang cố gắng đạt đến độ trưởng thành của phần mềm chuyên dụng
Podsqueeze
Podsqueeze được trình bày như một nền tảng sản xuất podcast được hỗ trợ bởi AI vượt quá xử lý âm thanh đơn giản. Nó tập trung vào tự động hóa quy trình làm việc hoàn chỉnh từ cải thiện âm thanh đến tạo nội dung cho tiếp thị và mạng xã hội.
Những gì nó làm tốt: Giống như Auphonic, Podsqueeze xử lý tiếng ồn nền dữ dội, phản xạ rõ ràng và mất cân bằng âm lượng rất tốt, miễn là giọng nói gốc trung thực. Điều này bao gồm các bản ghi được thực hiện với:
- Micro bình thường
- Môi trường nhà không hoàn hảo
- Âm thanh được chụp bởi điện thoại
Nó đặc biệt mạnh trong các kịch bản với nhiều người nói, đảm bảo âm lượng nhất quán và dễ hiểu trong suốt tập phát sóng. Điều này hoạt động ngay cả khi điều kiện ghi âm khác nhau giữa các người tham gia.
Âm thanh được tăng cường duy trì tông màu con người của giọng nói mà không cần đến tái tổng hợp tích cực. Điều này tránh các hiện tượng không mong muốn kim loại, giọng nói robot, hoặc hiệu ứng "kỹ thuật số" phổ biến trong các công cụ AI khác.
Không giống như các công cụ tăng cường âm thanh cô lập, bộ tăng cường âm thanh của Podsqueeze là một phần của hệ sinh thái được thiết kế đặc biệt cho podcast. Nó được tích hợp với:
- Tính năng phiên âm
- Chỉnh sửa dựa trên văn bản
- Tái sử dụng nội dung
Cải thiện âm thanh hoàn toàn tự động và tạo ra kết quả nhất quán giữa các tập phát sóng. Không cần điều chỉnh các tham số kỹ thuật hoặc đưa ra quyết định kỹ thuật âm thanh.
Nó cho phép chỉnh sửa âm thanh bằng cách loại bỏ từ trực tiếp từ phiên âm. Đây là một tiết kiệm thời gian lớn so với chỉnh sửa dạng sóng truyền thống.
Nó nổi bật với khả năng tự động tạo clip ngắn cho TikTok, Reels và YouTube Shorts từ các tập dài. Điều này tạo điều kiện phân phối và tái sử dụng nội dung podcast.
Nó cung cấp quản lý nhiều chương trình, cho phép tổ chức nhiều podcast trong thư mục với cài đặt cụ thể cho mỗi chương trình. Điều này đơn giản hóa quản lý nhiều chương trình hoặc khách hàng.
Podsqueeze là giải pháp thực tế và đáng tin cậy cho người sáng tạo muốn kết quả tốt mà không có quy trình làm việc kỹ thuật phức tạp.
Nơi nó gặp khó khăn
-
Podsqueeze không được chỉ định cho việc tái tạo các giọng nói bị suy giảm cao hoặc bị nén. Ví dụ bao gồm bản ghi cuộc gọi điện thoại hoặc âm thanh với mất thông tin phổ nghiêm trọng. Trong những trường hợp này, công cụ tái tổng hợp giọng nói có thể tạo ra kết quả "ấn tượng" hơn.
-
Trọng tâm là kết quả cuối cùng và không phải điều chỉnh thủ công chi tiết các tham số kỹ thuật. Điều này có thể hạn chế các kỹ sư âm thanh tìm kiếm kiểm soát phẫu thuật trên mỗi bước xử lý.
-
Mặc dù bộ tăng cường âm thanh về mặt kỹ thuật vững chắc, giá trị lớn nhất của nó xuất hiện khi được sử dụng trong quy trình làm việc sản xuất và tái sử dụng podcast hoàn chỉnh.
-
Nếu bạn chỉ cần cải thiện một tệp âm thanh thỉnh thoảng, không quan tâm đến phiên âm, chỉnh sửa, hoặc tái sử dụng, các công cụ dành riêng cho tăng cường âm thanh có thể là lựa chọn đơn giản và trực tiếp hơn.
Tốt nhất cho
Người làm podcast hoặc người sáng tạo nội dung âm thanh lặp lại, khi:
- Bản ghi có giọng nói trung thực ngay cả với tiếng vang hoặc tiếng ồn nền nghiêm trọng
- Có phỏng vấn với nhiều người nói và âm lượng không nhất quán
- Có quan tâm đến việc tái sử dụng tập phát sóng cho clip và mạng xã hội
Đối với người sáng tạo có mục tiêu chỉ là cải thiện nhanh một tệp âm thanh cô lập, các giải pháp đơn giản hơn tập trung độc quyền vào tăng cường âm thanh có thể có ý nghĩa hơn.
Nhưng đối với người làm podcast tìm kiếm quy trình làm việc tích hợp, nhất quán và hiệu quả, Podsqueeze nổi bật như một giải pháp vững chắc được điều chỉnh tốt cho đối tượng mục tiêu của nó.
LALAL.AI
LALAL.AI được công nhận rộng rãi như một công cụ bắt đầu chuyên về tách stem (chia giọng nói từ nhạc cụ) và phát triển thành nền tảng xử lý âm thanh hoàn chỉnh với khả năng loại bỏ tiếng ồn và tiếng vang.
Những gì nó làm tốt: Nó là công cụ "mạnh mẽ điên rồ" để tạo phân chia âm thanh. Nó có khả năng tách giọng nói từ nhạc nền trong tình huống nơi các công cụ khác thất bại.
Tôi phát hiện ra LALAL.AI có thể vượt qua gói iZotope RX (tiêu chuẩn ngành) khi xử lý âm thanh "thực sự khó" hoặc bị suy giảm.
Nó là công cụ lựa chọn nếu bạn cần trích xuất đối thoại từ tài liệu "bị đánh cắp" hoặc mua từ nguồn bên ngoài với nhạc được bảo vệ bản quyền.
Tôi đã sử dụng công cụ để loại bỏ nhạc từ quảng cáo đã được trộn trong stereo. Điều này cho phép tạo tài liệu trình bày mới (sizzle reels) với giọng nói sạch.
Giao diện web được coi là thẳng thắn và dễ sử dụng, cho phép tải lên tệp và kết quả nhanh chóng mà không có cấu hình phức tạp.
Không giống như đăng ký hàng tháng cứng nhắc, nó cung cấp mô hình thanh toán trả tiền khi sử dụng. Điều này rất hấp dẫn cho người sáng tạo chỉ cần làm sạch âm thanh thỉnh thoảng.
Nơi nó gặp khó khăn
-
Nếu công cụ phải "làm việc quá chăm chỉ" để làm sạch tiếng ồn hoặc nhạc, âm thanh cuối cùng có thể trở nên chói tai, kim loại và bị nén quá mức.
-
Sau khi loại bỏ nhạc, tôi nhận thấy một tiếng vang tinh tế có thể vẫn còn trong đối thoại. Điều này yêu cầu sử dụng các công cụ bổ sung (như giảm reverb trong Premiere) để đánh bóng kết quả.
-
Trong thử nghiệm của tôi, LALAL.AI thỉnh thoảng cắt cuối cụm từ hoặc từ, gây hại cho độ trôi chảy giọng nói.
-
Mặc dù nó cho phép xem trước, tải xuống tệp đã xử lý yêu cầu thanh toán gói phút.
-
Trong so sánh làm sạch giọng nói trực tiếp, LALAL.AI rơi xuống dưới Auphonic về chất lượng cuối cùng và bảo tồn giọng nói tự nhiên.
Tốt nhất cho
-
Biên tập viên cần trích xuất đối thoại từ tình huống không thể
-
Chuyên gia làm việc với nhạc được bảo vệ bản quyền cần loại bỏ
-
Bất kỳ ai đối mặt với thách thức tách âm thanh mà các công cụ khác không thể xử lý
-
Tuy nhiên, sự hoàn hảo có giá. Bạn phải chuẩn bị đối phó với một số mất mát độ trung thực hữu cơ để đổi lấy tách giọng hát mà ít công cụ khác có thể đạt được
-
Nó không nhất thiết là lựa chọn đầu tiên cho đánh bóng hàng ngày của một podcast được ghi tốt, nhưng nó là "vũ khí bí mật" cho các cứu hộ không thể
Khuyến nghị nhanh theo ý định
Chọn các công cụ tốt nhất để tăng cường âm thanh phụ thuộc vào nhu cầu cụ thể và quy trình làm việc của bạn. Đây là các khuyến nghị nhanh dựa trên các kịch bản phổ biến:
Chọn AudioEnhancer.com nếu: Bạn cần làm sạch âm thanh đáng tin cậy, tự nhiên mà không có độ phức tạp kỹ thuật. Nó hoàn hảo khi điều kiện ghi âm không lý tưởng nhưng giọng nói gốc trung thực, và bạn muốn kết quả chất lượng phòng thu nhanh chóng với quy trình làm việc tải lên-xử lý-tải xuống đơn giản.
Chọn Adobe Podcast Enhance Speech nếu: Bạn cần cứu các bản ghi từ môi trường khủng khiếp, làm việc với thiết lập ghi âm không nhất quán, hoặc muốn cải thiện nhanh mà không có kiến thức kỹ thuật. Nó lý tưởng cho tình huống khẩn cấp hơn là phương pháp sản xuất chính, đặc biệt cho nội dung độ trung thực cao như sách nói nơi âm thanh được xử lý bởi AI có thể bị từ chối vì nghe "không phải con người".
Chọn Auphonic nếu: Bản ghi gốc của bạn đã hợp lý và bạn muốn âm thanh chuyên nghiệp, trung thực duy trì động lực giọng nói tự nhiên. Nó hoàn hảo cho nhiều người nói cần âm lượng nhất quán, nhà sản xuất tập hàng tuần muốn chữ ký âm thanh giống hệt nhau, và bất kỳ ai thấy Adobe Podcast quá nhân tạo.
Chọn Cleanvoice AI nếu: Bạn có tics lời nói, sự do dự thường xuyên, hoặc âm thanh miệng nổi bật sẽ không thể chỉnh sửa thủ công. Nó lý tưởng nếu bạn ghét âm thanh tổng hợp/robot và thích duy trì kết cấu giọng nói gốc, chấp nhận rằng tiếng ồn nền có thể không được loại bỏ hoàn toàn.
Chọn Descript Studio Sound nếu: Bạn coi trọng tốc độ và đã sử dụng nền tảng cho chỉnh sửa video nhiều camera hoặc phiên âm. Hãy thận trọng nếu bạn làm việc với giọng không phải Mỹ hoặc cần độ trung thực âm thanh tối đa, vì nó có thể hy sinh tự nhiên để đổi lấy độ sạch hoàn toàn.
Chọn DaVinci Resolve Voice Isolation nếu: Bạn là biên tập viên video muốn làm sạch âm thanh chuyên nghiệp mà không rời khỏi môi trường chỉnh sửa của bạn. Nó yêu cầu giấy phép Studio nhưng cung cấp sự đơn giản một nút cạnh tranh với phần mềm chuyên dụng đắt tiền.
Chọn Krisp nếu: Bạn cần ức chế tiếng ồn thời gian thực cho cuộc gọi trực tiếp, phát trực tuyến, hoặc công việc từ xa. Sử dụng với thận trọng cho bản ghi chuyên nghiệp yêu cầu độ trung thực tối đa, vì nó có thể suy giảm chất lượng giọng nói.
Chọn Eleven Labs Voice Isolator nếu: Bạn cần cứu âm thanh nơi giọng nói phải nghe thực và con người nhất có thể mà không có các hiện tượng không mong muốn kim loại. Hãy chuẩn bị xử lý không nhất quán âm lượng và chấp nhận rằng tách có thể không 100% im lặng trong tiếng ồn cực đoan.
Chọn Riverside.fm nếu: Bạn sản xuất podcast phỏng vấn từ xa nơi chất lượng hình ảnh và âm thanh là ưu tiên. Nhiều chuyên gia xuất tệp thô sang trình chỉnh sửa chuyên dụng cho công việc cuối cùng, sử dụng Riverside chủ yếu như trạm chụp.
Chọn Podsqueeze nếu: Bạn là người làm podcast lặp lại muốn quy trình làm việc tích hợp với phiên âm, chỉnh sửa dựa trên văn bản và tái sử dụng nội dung. Nó ít lý tưởng nếu bạn chỉ cần cải thiện các tệp âm thanh cô lập thỉnh thoảng.
Chọn LALAL.AI nếu: Bạn cần trích xuất đối thoại từ tình huống không thể, loại bỏ nhạc được bảo vệ bản quyền, hoặc đối mặt với thách thức tách âm thanh mà các công cụ khác không thể xử lý. Nó là "vũ khí bí mật" của bạn cho các cứu hộ không thể, mặc dù bạn có thể hy sinh một số độ trung thực hữu cơ.
Kết luận
Các công cụ tốt nhất để tăng cường âm thanh năm 2026 cung cấp các cách tiếp cận khác nhau để cải thiện chất lượng âm thanh. Một số sử dụng tái tổng hợp AI tích cực để xây dựng lại âm thanh từ đầu. Những công cụ khác tập trung vào xử lý bảo thủ bảo tồn đặc tính gốc. Một số xuất sắc ở các nhiệm vụ cụ thể như loại bỏ tiếng ồn, trong khi những công cụ khác cung cấp quy trình làm việc hoàn chỉnh.
Chìa khóa là khớp công cụ với nhu cầu của bạn. Nếu bạn đang làm việc với âm thanh bị hỏng nghiêm trọng, các công cụ như Adobe Podcast hoặc LALAL.AI có thể thực hiện phép màu. Nếu bạn muốn đánh bóng tự nhiên mà không có các hiện tượng không mong muốn robot, Auphonic hoặc Podsqueeze cung cấp sự cân bằng tốt hơn. Đối với kịch bản thời gian thực, Krisp dẫn đầu. Đối với quy trình làm việc video tích hợp, DaVinci Resolve hoặc Riverside.fm xuất sắc.
Nhiều chuyên gia sử dụng nhiều công cụ trong quy trình làm việc của họ, áp dụng mỗi công cụ nơi nó hoạt động tốt nhất. Yếu tố quan trọng nhất không phải là tìm công cụ "tốt nhất" duy nhất, mà là hiểu những gì mỗi công cụ làm tốt và khi nào sử dụng nó.
Bắt đầu với điểm đau lớn nhất của bạn, thử nghiệm một vài tùy chọn với các bản ghi thực tế của bạn, và xây dựng bộ công cụ của bạn từ đó.