Adobe Speech Enhancer vs Auphonic vs AudioEnhancer.com: qual deves usar?

Se estás a comparar Adobe Podcast Enhance Speech, Auphonic e AudioEnhancer.com, estás a olhar para três ferramentas muito sólidas.
Todas conseguem limpar áudio, melhorar clareza e entregar resultados com qualidade profissional.
As diferenças começam a importar quando olhas para como cada uma trata a voz original, quão “mãos-na-massa” é o controlo e quão tolerante é o processamento em condições extremas.
Esta comparação foca-se nessas nuances para te ajudar a escolher o melhor fit para o teu workflow.
Quick comparison (TL;DR)
- Melhor para resultados naturais, profissionais e consistentes: AudioEnhancer.com
- Melhor para controlo técnico e masterização “broadcast-grade”: Auphonic
- Melhor para resgatar áudio muito degradado: Adobe Speech Enhancer
AudioEnhancer.com
Som natural, alta fiabilidade e workflow sem fricção
Na minha experiência, o AudioEnhancer.com fica num ponto muito confortável entre potência e simplicidade.
Funciona muito bem em condições reais, incluindo ruído de fundo extremo, eco forte, plosives, mouth clicks, respirações e desequilíbrios grandes de volume.
Desde que a voz seja reconhecível, os resultados mantêm-se naturais e estáveis, sem os artefactos metálicos/robóticos que podem aparecer em abordagens mais agressivas.
Uma coisa que notei de forma consistente é o quão previsível é o output.
Mesmo quando o empurras, a voz mantém clareza e brilho, especialmente em gravações com eco onde o Adobe pode ficar um pouco mais abafado.
A interface é intencionalmente minimal: upload, processar, download.
Sem presets.
Sem jargão técnico.
Sem curva de aprendizagem.
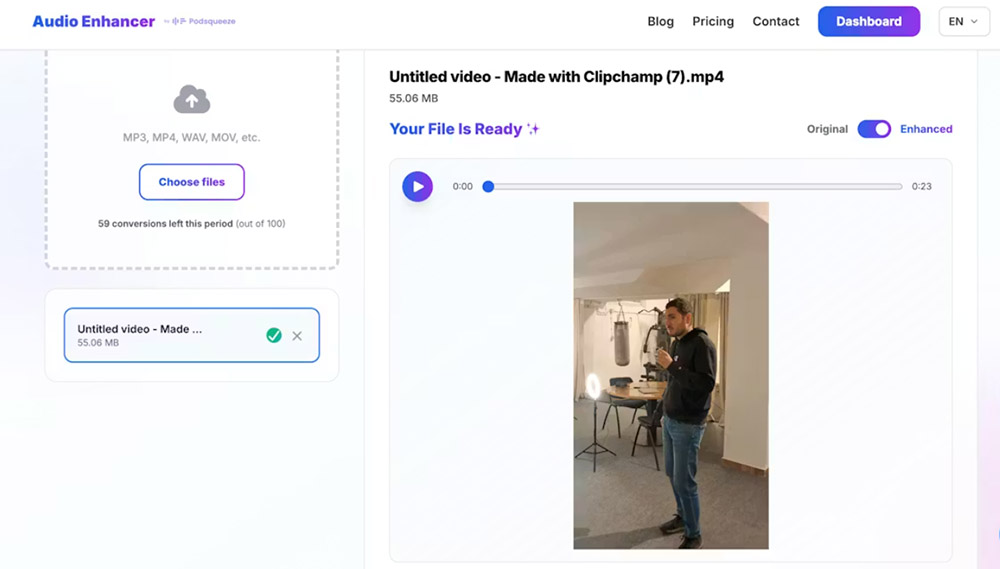
E funciona com áudio e vídeo, o que é prático para podcasts, YouTube, entrevistas e UGC.
Onde o AudioEnhancer.com traça um limite claro é na ressíntese.
Ele não tenta reconstruir vozes extremamente degradadas, como chamadas telefónicas muito comprimidas em alta-voz num carro.
Ele limpa e melhora gravações reais, preservando identidade vocal.
Perfeito para
- Criadores que querem resultados naturais e com “cara” profissional
- Áudio com ruído severo, eco, plosives, mouth clicks e respiração
- Gravações com microfones ou telemóvel
- Entrevistas com grandes diferenças de volume entre oradores
- Quem valoriza interface simples e resultados rápidos
- Cenários em que a voz é reconhecível, mas não está “destruída”
Auphonic
Consistência “broadcast-grade” e controlo técnico
O Auphonic é, há muito, visto como um “gold standard” de masterização automática para podcasters e profissionais de áudio, e a reputação faz sentido.
A filosofia é clara: polir o original, sem o substituir.
Em vez de ressíntese agressiva, o Auphonic foca-se em otimização técnica.
Coisas como Intelligent Leveler, normalização de loudness para padrões (-14 LUFS YouTube, -16 LUFS podcasts) e Crossgate (para reduzir mic bleed em setups multi-microfone) tornam-no excelente para entrevistas e shows recorrentes.
Na prática, isto dá resultados muito consistentes entre episódios.
As vozes soam equilibradas, com dinâmica controlada e um som honesto e humano.
Os módulos DeBreath e DeClick também fazem um trabalho muito bom a remover respirações e estalidos sem chamar atenção.
O Auphonic também brilha em workflows profissionais por causa de automação e reprocessamento.
Poder ajustar settings e reprocessar sem pagar extra é uma vantagem real em produção contínua.
Dito isto, ele exige um pouco mais do utilizador.
A interface é mais “datada”, e a terminologia (LUFS, gating, crossgate) pode intimidar quem não é técnico.
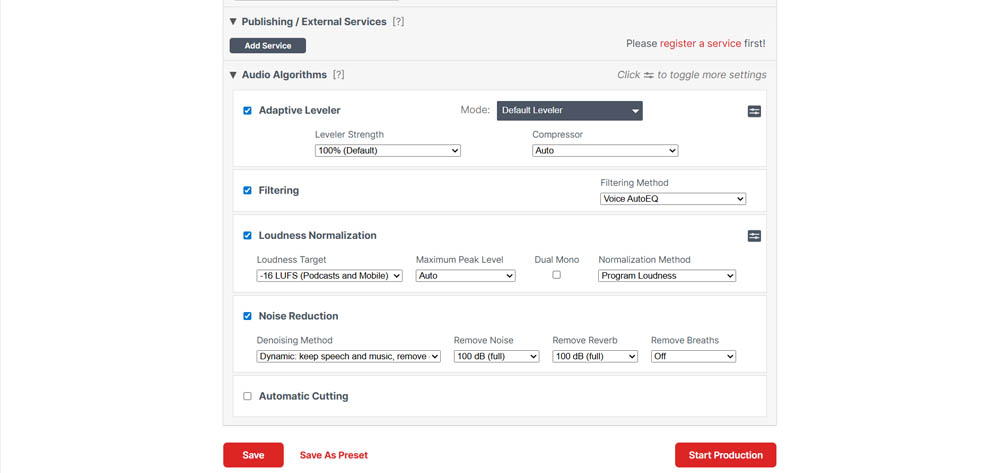
Não é difícil, mas é menos “plug-and-play” do que o AudioEnhancer.com.
E não é uma ferramenta de milagres.
Se o áudio for caos absoluto, não vai isolar fala como o Adobe às vezes consegue.
Perfeito para
- Podcasters que querem consistência entre episódios
- Entrevistas com múltiplos oradores e múltiplos microfones
- Criadores que se preocupam com padrões de loudness (broadcast)
- Profissionais que querem mais controlo técnico e presets
- Quem quer um som natural e evita abordagens demasiado artificiais
- Equipas que valorizam automação e repetibilidade
Adobe Podcast Enhance Speech
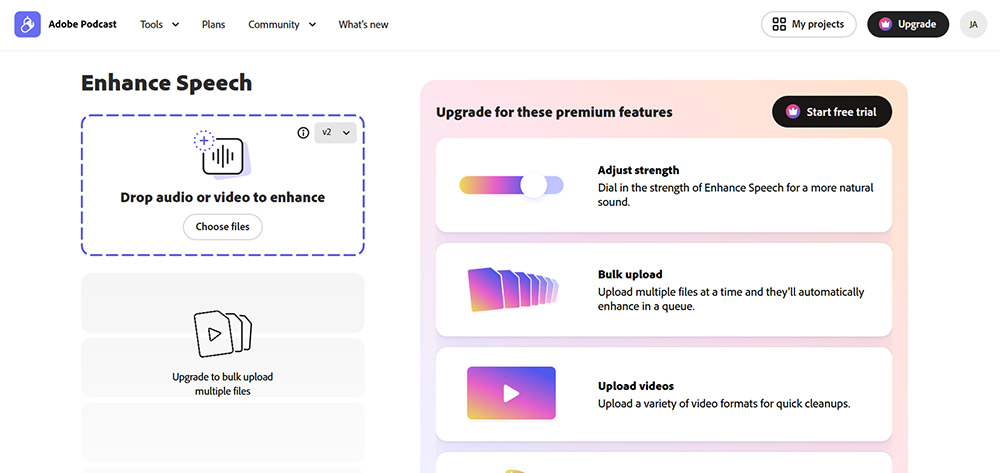
Resgate de áudio extremo via ressíntese
O Adobe Speech Enhancer é a ferramenta mais agressiva e polarizante desta comparação.
A força está na ressíntese.
Em vez de apenas limpar o sinal original, ele gera uma nova voz que imita o orador.
Isto torna-o muito poderoso quando o áudio está mesmo mau, com ruído pesado, vento, maquinaria, vozes sobrepostas e compressão forte.
Em áudio tipo “telefone” ou gravações em ambientes impossíveis, o Adobe muitas vezes dá o resultado mais inteligível das três.
O downside é a previsibilidade.
Como a voz é reconstruída, podem aparecer artefactos: tons metálicos, texturas robóticas e, por vezes, “alucinações” em inputs muito ruidosos.
A versão gratuita não tem controlo de intensidade, o que aumenta o risco de overprocessing.
A versão paga melhora bastante quando usada de forma conservadora.
A interface é simples e rápida, muito drag-and-drop.
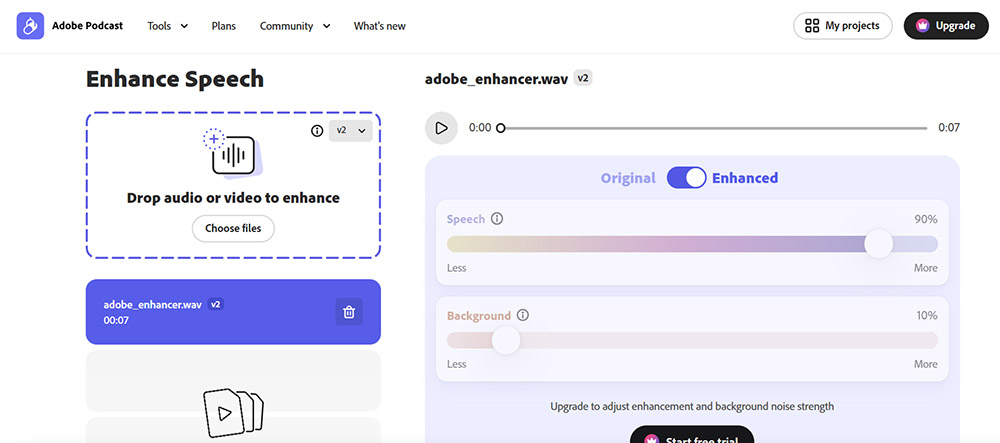
Eu vejo o Adobe como uma ferramenta de resgate, não como “daily driver” para conteúdo profissional de alta fidelidade.
Perfeito para
- Áudio muito degradado ou comprimido
- Gravações em ambientes caóticos e sem controlo
- Casos em que reconstrução de voz é necessária
- Limpeza de emergência / “último recurso”
- Quem quer um workflow drag-and-drop simples
- Cenários em que algum risco de artefactos é aceitável
Veredito final: escolher a ferramenta certa
Não existe um “best” universal aqui.
Cada ferramenta é excelente dentro da sua filosofia.
- Se queres resultados naturais, fiáveis e profissionais com o mínimo de esforço, AudioEnhancer.com é a escolha mais segura e consistente.
- Se queres controlo técnico, consistência de loudness e masterização repetível, o Auphonic continua a ser um standard, especialmente para podcasts e entrevistas.
- Se precisas de resgatar áudio extremamente degradado, o Adobe Speech Enhancer consegue coisas que os outros não conseguem, com o trade-off de possíveis artefactos.
No fundo, a decisão não é “qual tem melhor qualidade em abstrato”.
É quanto controlo precisas, quão mau é o áudio de origem e quanta fricção aceitas no teu workflow.