2026年にオーディオとスタジオ音質を改善する最高のツール

2026年、プロフェッショナル品質のオーディオはこれまで以上にアクセスしやすくなっています。自宅からポッドキャストを録音している、フィールドインタビューをクリーンアップしている、またはナレーションを磨いている場合でも、適切な強化ツールは平凡な録音をスタジオレベルの音に変換できます。
課題は、機能するツールを見つけることではなく、ワークフロー、予算、品質の期待に合うものを選ぶことです。
このガイドは、今日利用可能な主要なオーディオ強化ツールを調査します。各ツールは音質を改善するために異なるアプローチを取ります。一部は積極的なAI音声再合成を使用して、最初からオーディオを再構築します。他のツールは、元の音声の特性を保持する保守的な処理に焦点を当てます。
一部は背景ノイズの除去に優れ、他のツールはレベル調整、マスタリング、または口頭の癖の除去に特化しています。
あなたに最適なツールは、何を扱っているか、何を達成する必要があるかに依存します。以下では、各ツールの強み、制限、理想的なユースケースを探ります。最後に、一般的なシナリオと意図に基づいたクイック推奨事項を見つけます。
AudioEnhancer.com
AudioEnhancer.comは、音を迅速かつ直接的にクリーンアップ、バランス調整、プロフェッショナル化するように設計されたAIを活用したオーディオおよびビデオ強化プラットフォームです。焦点は、不要な機能や技術的複雑さなしで、シンプルなフロー:アップロード、処理、ダウンロードにあります。
優れている点: 元の音声が忠実である限り、重い背景ノイズ、激しい残響、クリッピング、破裂音、主要な音量の不均衡を非常にうまく処理することがわかりました。以下で作られた録音で一貫して機能します:
- 専用マイク
- ポータブルレコーダー
- 電話マイク
処理は人間の音色の保持を優先し、積極的な再合成アプローチで一般的なロボット音声、金属的な音、またはデジタルアーティファクトを回避します。
複数の話者を含むコンテンツで特に効果的で、録音全体を通じて一貫した理解可能なレベルを保証します。
入力 → 処理 → ダウンロードへの排他的な焦点により、複雑なダッシュボードや長いワークフローなしで、即座の結果が必要な場合にツールを理想的にします。
オーディオとビデオファイルの両方をサポートしており、YouTube、ソーシャルメディア、ビデオインタビュー、またはUGC向けのコンテンツに有用です。
ダッシュボードは最小限で使いやすく、学習曲線なしで特定の問題を解決したいユーザー向けに設計されています。
予測可能で一貫した動作により、ツールは安定性と自然さを重視するクリエーターとプロフェッショナルによる繰り返し使用に適しています。
苦労する点
-
AudioEnhancer.comは、高度に劣化または圧縮された音声を再構築するための最良のオプションではありません。例には、電話通話録音や深刻なスペクトル情報損失のあるオーディオが含まれます。
-
ツールは結果指向であり、パラメータの詳細な手動微調整を提供しません。これは、各処理ステップで外科的コントロールを求める高度なオーディオエンジニアリングユーザーを制限する可能性があります。
-
音質改善に排他的に焦点を当てています。編集、転写、またはコンテンツの再利用機能を含まないため、他のワークフローで追加のツールが必要になる場合があります。
最適な用途
AudioEnhancer.comは、実際の録音条件でオーディオとビデオをクリーンアップし、プロフェッショナル化するための極めて信頼性の高いツールです。
特に推奨されるのは:
- 録音条件が理想的ではなかった場合(エコー、ノイズ、クリッピング)
- 目標が迅速にスタジオ音を取得すること
- 優先順位がシンプルさ、予測可能性、自然さである場合
「人工的な奇跡」のツールではなく、技術的な摩擦なしで一貫した自然な結果を必要とするコンテンツクリエーターとプロフェッショナル向けに設計された、堅牢で安定したオーディオクリーンアップツールです。
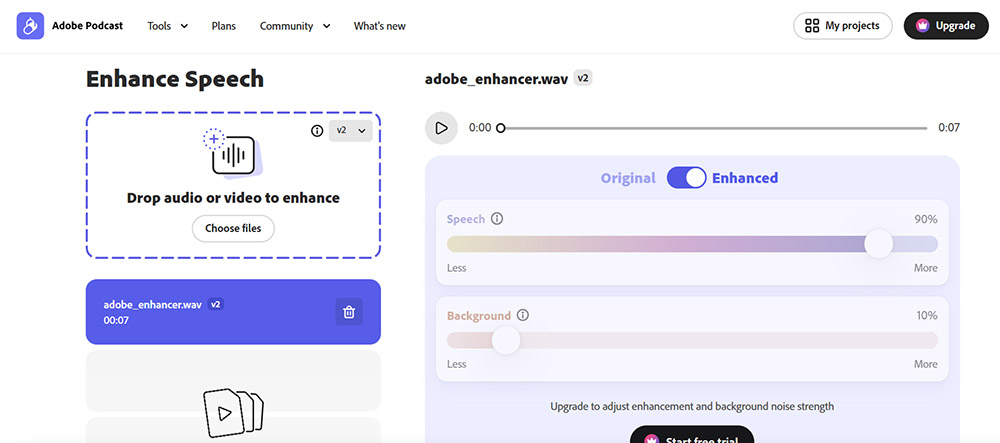
Adobe Podcast Enhance Speech
Adobe Podcast Enhance Speech(以前のProject Shasta)は、低品質の音声録音を、プロフェッショナルなスタジオでキャプチャされたように聞こえるオーディオに変換するために深層学習モデルを使用するブラウザベースのツールです。
技術は音声再合成に依存しており、AIはノイズをフィルタリングするだけでなく、元の話者の音色を模倣する新しい音声を生成します。
優れている点: 不可能な環境で録音されたオーディオを回復することに本当に印象的であることがわかりました。これには以下が含まれます:
- ノイズの多いコンベンションホール
- 不安定なWi-Fiのあるホテル
- 激しい交通のある忙しい通り
風、産業用ファン、掃除機、建設機械、背景音楽を含む特定の種類のノイズの除去に優れています。ツールは、他の音声が重なっている場合でも主要な話者を分離できます。
マイクゲイン過負荷に苦しんだクリッピングされたオーディオを修復することに驚くほど効果的です。インターフェースはドラッグアンドドロップでシンプルで、学習曲線はゼロです。
マイクと口の間の一定の距離により、AirPods録音で特にうまく機能します。20ユーロのマイクを100ユーロのマイクのように聞こえさせることができます。
苦労する点
-
奇跡を可能にするのと同じ再合成技術が失敗し、音声を金属的、ロボット的、または奇妙に圧縮されたように聞こえさせる可能性があります。これは特にバージョンV2または元のノイズが過度に密な場合に発生します。
-
極端なノイズ条件下では、AIが話者が決して言わなかった音素や単語を発明する可能性があります。最終ファイルにランダムな音声を混ぜることさえできます。
-
Webバージョンは、ユーザーハードウェアをブロックしないように制限されているPremiere Pro統合よりも大幅に優れています。これは多くのプロフェッショナルを一定の往復ワークフローに強制します。
-
雰囲気を保持したい音楽や複雑な音響風景には適していません。ツールは人間の音声ではないすべてをクリーンアップしようとし、芸術的な意図を台無しにする可能性があります。
-
無料版は調整する設定を提供せず、自動結果に任されます。
最適な用途
-
貧弱な環境から録音を救う必要があるコンテンツクリエーター
-
一貫性のない録音セットアップで作業するポッドキャスター
-
技術的知識なしで迅速な改善を必要とする人
最も自然な音のために、強度スライダー(プレミアムで利用可能)を約70〜75%に設定することが最適点であることがわかりました。または、軽いノイズリダクションでオーディオを前処理し、その後20〜40%でAdobeの強化ツールを適用することは、最終仕上げにうまく機能します。
Auphonic
Auphonicは、「自然な仕上げ」の哲学の下で動作するクラウドベースのオーディオポストプロダクションサービスです。積極的な音声再合成を使用するAdobe Podcastのようなツールとは異なり、Auphonicは元の録音の技術的最適化に焦点を当てています。
ポッドキャスティングのベテランの間で、**自動マスタリングの「ゴールドスタンダード」**として広く考えられています。Auphonic vs Adobeを比較すると、技術的コントロールと積極的な再合成の違いが明確になります。
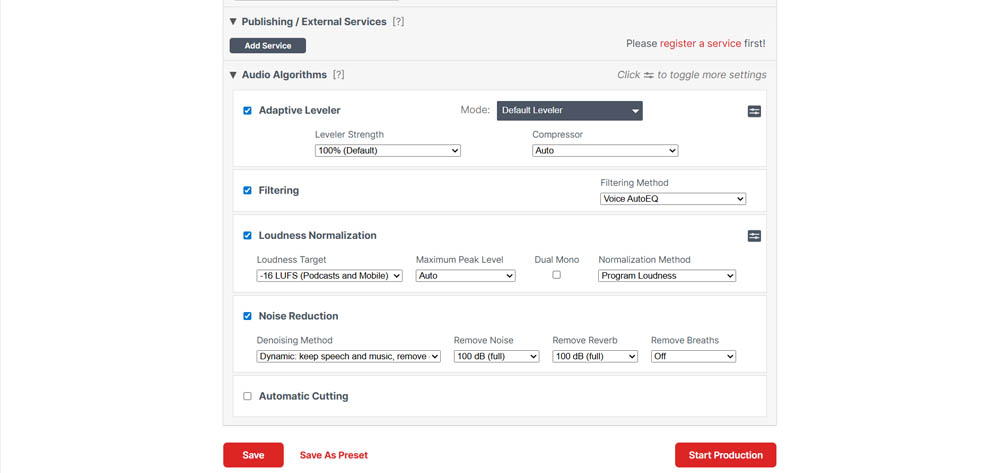
優れている点: Intelligent Levelerが最も称賛されている機能です。AIはファイルを分析し、異なる話者、音楽、サウンドエフェクト間のレベルを自動的にバランス調整します。これにより、複雑な手動コンプレッサーの必要性がなくなります。
オーディオがプラットフォームラウドネス標準を満たすことを保証するためのGo-toツールです。これには、YouTube用の-14 LUFSまたはポッドキャスト用の-16 LUFSが含まれ、オーディオが静かすぎたり歪んだりするのを防ぎます。
Crossgate機能は、同じ空間で複数のマイクを使用した録音で高く評価されています。1人の音声が別のマイクによってキャプチャされたときにマイクブリードを劇的に減らします。
呼吸除去アルゴリズムは、手動編集の時間を節約するのに十分にうまく機能する市場で数少ないものの1つと考えられています。また、口のクリックや不自然な沈黙を効果的に除去します。
帯域幅拡張は、失われたように見えた周波数を復元することで、こもったまたは低品質の録音に生命を戻すことができます。
ユニークな利点は、すでに処理されたファイルの設定を変更し、本番を再実行することを決定した場合、Auphonicが追加のクレジットを請求しないことです。
以下をサポートする「設定して忘れる」ワークフローを提供します:
- メタデータ
- 自動ショーノート
- チャプター
- 複数言語でのWhisperによる転写
苦労する点
-
AuphonicはAdobeのような「奇跡の再合成」ツールではありません。元のオーディオに極めて積極的な背景ノイズや残響がある場合、Auphonicは新しい生成モデルほど音声を分離できない可能性があります。
-
Webプラットフォームのデザインは、現代の2025年の視覚標準と比較して時代遅れに感じられます。
-
多くのパラメータを提供しますが、一部の機能はリンクされています。たとえば、DeBreathアルゴリズムは時々ノイズリデューサーに結び付けられており、広帯域ノイズに対する呼吸削減レベルの独立した調整を防ぎます。
-
無料版(月に2時間を提供)は、処理された本番の開始または終了に小さなオーディオジングルを追加します。
-
特定の設定で音楽をうまく処理しますが、その主な強みは対話です。純粋な音楽マスタリングには理想的ではない可能性があります。
最適な用途
自然な音声ダイナミクスを保持しながら、AIロボットのように聞こえないプロフェッショナルで誠実な音を望むポッドキャスター。以下で理想的です:
- 元の録音がすでに合理的である場合
- 一貫した音量が必要な複数の話者がいる場合
- クリエーターが週次エピソードを制作し、すべてのコンテンツで同一の音響署名を望む場合
Adobe Podcastが過度に人工的であるか、金属的なアーティファクトに気づく場合、Auphonicは完璧なバランスを提供します。
Cleanvoice AI
Cleanvoice AIは、微小音響の問題と口頭の癖に焦点を当てることによって区別されるクラウドベースのポストプロダクションツールです。環境ノイズのみを減らすツールとは異なり、Cleanvoiceは、ポッドキャストリスニングを疲れさせる生物学的要素と躊躇を識別および除去するように特別に訓練されています。
優れている点: 20以上の言語で「えーっと」「あー」「みたいな」などのフィラーワードを自動的に検出することに非常に効果的です。
競合他社のDescriptよりも「外科的」と説明されており、以下を除去します:
- 口の音
- クリック
- 唇の音
- 重い呼吸
その最大の強みの1つは、Adobe Podcastほど積極的に元の音声の音色を変更しないことです。自然な音声のリズムを保持し、気を散らすもののみを除去します。CleanVoice vs Adobe比較は、各ツールが異なるノイズシナリオをどのように処理するかを示しています。
自動的な破壊的な変更を適用するのではなく、Cleanvoiceは提案のタイムラインを提示します。これにより、編集を個別に承認または拒否できます。
「デッドエア」(延長された沈黙)を効率的に識別および除去し、手動の努力なしでコンテンツのリズムを改善します。
苦労する点
-
実質的な背景ノイズまたは非常にノイズの多い環境に直面した場合、処理されたオーディオは「ピクセル化」「しわくちゃ」、または奇妙なオートチューン効果で聞こえ始める可能性があります。
-
転写サービスを提供しているにもかかわらず、結果は失望的であることがわかりました。Audacityのような無料ソフトウェアは、この特定の領域で優れた結果を達成します。
-
オーディオクリーンアップツールであり、完全なエディターではありません。堅牢なビデオ編集機能やリアルタイム処理機能が欠けています。
-
処理時間に基づく価格モデル(例:10時間で11ユーロ)は、大量のコンテンツを制作する場合、高価になる可能性があります。
-
ノイズを除去しますが、大きな部屋での残響の処理では、AdobeやiZotope RXほど効果的ではありません。場合によっては、「ピクセル化」された結果よりも元のオーディオを好みました。
最適な用途
-
口頭の癖があるポッドキャスター
-
頻繁に躊躇したり、長いエピソードで手動で編集することが不可能な顕著な口の音があるクリエーター
-
Adobeの合成的/ロボット的な音を嫌い、音声の元のテクスチャを維持することを好む場合。より大きな忠実度と引き換えに、背景ノイズが完全に除去されない可能性があることを受け入れる必要があります
-
AIにエラーの発見の重い作業をさせたいが、提案システムを通じて何がカットされるかについて最終決定権を持ちたい編集者
Descript Studio Sound
Descript Studio Soundは、単なるシンプルなオーディオプロセッサではなく、テキストベースの編集を通じて生産性を再定義するオールインワン編集エコシステム内の中心的な機能です。
その効率に感銘を受けましたが、処理された音のテクスチャについて特定の批判があります。
優れている点: 最大の利点は、Studio Soundがテキストドキュメントのようにオーディオを編集するワークフローに統合されていることです。
ワンクリックで背景ノイズ、エコー、残響を除去しながら、同時にフィラーワード(「えーっと」と「あー」)と沈黙を除去する能力は、生産速度にとって無類のソリューションと見なされています。Descript vs Adobe比較は、ワークフローの違いが実際の使用にどのように影響するかを強調しています。
私のテストでは、Descriptは「悪いから良い」および「良いから優秀」へのオーディオの変換で私を驚かせました。明瞭度と、平凡な録音をプロフェッショナルなコンテンツに使用可能にする能力について、8/10と評価します。
ツールは、「ブリキ缶」や古い電話を通じて記録されたなど、悲惨な条件で録音されたオーディオを回復し、聞こえやすくクリーンにすることができます。
純粋なオーディオ改善を超えて、DescriptはOverdub(再録音なしでエラーを修正する音声クローニング)やAIを活用した視線接触調整などのツールを提供します。これらは、ビデオとポッドキャスト作成体験を補完します。
一部の自動ツールとは異なり、Descriptはスライダーを通じてStudio Soundエフェクトの強度を調整することを許可します。これにより、完全な清潔さと自然さの間のバランスを見つける自由が得られます。
苦労する点
-
繰り返しの批判は、Studio Soundが「金属的」または「ロボット的」な音を生成する可能性があることです。これは特に、アルゴリズムが重いノイズでファイルを処理することを強制された場合、または最大強度で適用された場合に発生します。
-
AIが単語が融合するアクセントを処理する際に苦労することを気づきました。これにより、突然のカット、オーディオ「ジャンプ」、または望ましくないデジタルの吃音が発生します。
-
音声クローニング機能は技術的に印象的ですが、生成された音声は感情がないか「死んでいる」ように聞こえる可能性があります。これは、過度に合成的なトーンを避けるために、一定の人間の監督を必要とします。
-
100%クラウドツール(Adobeなど)とは異なり、Descriptはコンピューターの処理能力を使用します。これは、ツールのパフォーマンスと適用速度が利用可能なハードウェアに直接依存することを意味します。
-
エクスポートと公開プロセスは奇妙で、時には遅く感じられます。特にシンプルなWebツールと比較して。
-
プロフェッショナルプランのサブスクリプション(約35米ドル/月)は、時折または独立したクリエーターにとって禁止的です。無料または従量課金の代替手段を求めることになるかもしれません。
最適な用途
-
速度を重視し、すでにマルチカメラビデオ編集や転写にプラットフォームを使用している制作チーム
-
ただし、最大の音響忠実度を求めている場合、または非アメリカのアクセントで作業している場合、結果を注意深く聞いてください。ツールは絶対的な清潔さのために自然さを犠牲にする可能性があります
-
オーディオに「フェイスリフトを与える」ツールと見なされていますが、誤用されると、人間の音声から「心」と感情を除去する可能性があります
DaVinci Resolve Voice Isolation
DaVinci Resolve Voice Isolationは、プロフェッショナルなオーディオ復元機能を直接ビデオ編集ワークフローに持ち込んだ革命的なツールです。専用の高価なソフトウェアに匹敵するパフォーマンスを見つけましたが、特定の技術的制限があります。
優れている点: 最も印象的な特性は、ワンノブソリューションであることです。はるかに少ない努力と手動調整で、iZotope RX Advanced(業界標準)に匹敵または優れた結果を達成しました。
ツールは、極めてノイズの多い環境で音声を分離することが証明されています。例には、ジェットエンジンの隣で録音されたインタビューや、背景音楽と皿の音のあるノイズの多いレストランが含まれます。
一定のドローンとホワイトノイズ、エンジン音などの除去に特に効果的で、オーディオを完全に使用可能にします。
Adobe Podcast(Webバージョン)のようなツールとは異なり、Voice Isolationはソフトウェアに組み込まれています。これにより、クリーンアップのためにファイルをエクスポートおよびインポートする必要性がなくなります。
ツールは、他のAIソリューションよりも少ないアーティファクトを導入し、ノイズを除去しながらより自然な音声を保持することがわかりました。
苦労する点
-
最も批判されているポイントの1つは、機能がDaVinci Resolveの無料版で利用できないことです。Studioライセンスの購入が必要です。
-
処理がリアルタイムで発生するため、タイムラインのプレビュー中にオーディオが「詰まる」または吃音する可能性があることに気づきました。これは特に、エフェクトが適用されたビデオセグメントで発生します。
-
強度が高すぎる場合、AIはノイズと非言語的な人間の表現を区別できない可能性があります。これにより、笑い、叫び、またはため息がカットされ、手動ADRが必要になる場合があります。
-
ツールは非常に短いクリップ(運転録音など)で望ましくない音調またはピッチの変更を導入することを気づきました。時々ノイズの処理に失敗したり、オーディオを完全にカットしたりします。
-
スペイン語話者でテストしたとき、結果は貧弱でした。これは、AIモデルが主に英語の音声で訓練された可能性があることを示唆しています。
最適な用途
-
編集環境を離れることなくプロフェッショナルなオーディオクリーンアップを望むビデオエディター
-
Adobe Podcast Enhanceは純粋なノイズ除去では依然としてわずかに優れていますが、Resolveはビデオエディターに統合されている便利さで勝ちます
-
RXが外科的コントロール(デクリック、デプラシブなど)を提供する一方で、Resolveは純粋な対話分離での速度に優れています。そのシンプルさのために「魔法」のように感じられます
-
Wavesのプラグインは、ハードウェア「しゃっくり」なしでより良いリアルタイムパフォーマンスを提供しますが、Resolveの分離はトップレベルです
Krisp
Krispは、リアルタイムオーディオ処理における無類のリーダーとして広く認識されています。ポストプロダクションでのみ動作する他のほとんどのツールとは区別されます。リアルタイム vs ポストプロダクションのトレードオフを理解することは、どのアプローチがワークフローに適合するかを決定するのに役立ちます。
マイクと録音または会議ソフトウェアの間のレイヤーとして機能し、AIを使用して、録音される前にオーディオをクリーンアップします。
優れている点: 予測不可能な家庭および都市のノイズを即座に除去することに優れています。例には、笑っている子供、吠えている犬、またはバタンと閉まるドアが含まれます。
ツールは低CPU消費を目的として設計されており、ビデオ通話や同時ストリーミングセッション中にコンピューターがパフォーマンスを失わないようにします。
800以上のアプリケーションで動作し、以下を含みます:
- Zoom
- Microsoft Teams
- Skype
- OBS
- AudacityなどのDAW
音声(マイク)をクリーンアップすることに加えて、Krispは通話の他の参加者からの着信オーディオ(スピーカー)もクリーンアップでき、それらの背景ノイズを除去します。
会議ノートの生成と無制限の転写のための自動ツールを含み、週次管理作業の時間を節約するのに役立ちます。
1日あたり60分の処理を提供する寛大な無料プランを提供します。これは、時折のクリエーターと時折の会議のプロフェッショナルに十分です。
苦労する点
-
積極的なノイズ除去の価格は、音声忠実度の劣化です。処理されたオーディオは「薄い」、わずかなエコー、または「フラット」でロボット的な質感で聞こえる可能性があります。
-
すでに静かな環境で高品質のスタジオマイクを使用してテストしたとき、Krispは「存在しないノイズを探す」ことを試みました。これにより、音声の明瞭度と自然な存在感が台無しになりました。
-
アクセントのローカライゼーション/変換機能を提供していますが、結果は失望的です。それらは一般的で不自然に聞こえ、元の音声の本質を捉えることに失敗します。
-
検証を必要とするツールとして、限られたオフライン機能があります。
-
生涯ライセンスから月額サブスクリプションモデルへの移行は、毎日使用しない人にとって魅力的でない可能性があります。
最適な用途
-
環境を制御できないリモートワーカー、ストリーマー、リアルタイム音声作業を行う人
-
注意して使用してください。ライブ放送や通話には正当ですが、「オーディオ涅槃」を要求するプロフェッショナルな録音では、DescriptやAdobeなどのより強力なツールでポストプロダクションで処理するために「汚い」音を録音する方が良いです。これにより、音声がソースから過度に処理されたように聞こえることを避けます
Eleven Labs Voice Isolator
Eleven Labs Voice Isolatorは、AIオーディオ処理市場で比較的最近のローンチです。Adobe Podcastほど議論されていませんが、すでに専門家コミュニティで強く対照的な意見を集めています。ElevenLabs vs Adobe比較は、各ツールが音声分離に異なるアプローチを取る方法を明らかにします。
優れている点: 音色の保持が最大の利点です。元の音声の音色を保持するために、両方のAdobeバージョン(WebとPremiere)よりもEleven Labsが優れていることがわかりました。
他のツールが積極的な再合成により音声を「合成的」に聞こえさせる可能性がある一方で、Eleven Labsは周囲のものを除去しながら有機的な音声アイデンティティを保持します。
音声ではないすべてを「剥がす」ことに非常に効果的です。音声が明確に定義されているが背景が混沌としている録音で話者を分離する必要がある場合に最適です。
直接の競合他社と同様に、深いオーディオエンジニアリング知識なしで迅速な結果を可能にする、簡略化された体験に焦点を当てています。
苦労する点
-
見つけた技術的な問題の1つは、ツールが望ましくないオーディオピーク(ピーキング)を引き起こす可能性があることです。これにより、処理後にリミッターまたは手動ゲイン調整を適用して歪みを避ける必要があります。
-
Adobe Podcastのようなツールとは異なり、時々「過度にクリーンアップ」(音素さえ除去)する一方で、Eleven Labsのアイソレーターは特定の条件下でまだいくつかの背景ノイズを通します。完全なクリーンアップでそれほど「容赦ない」ではありません。
-
アイソレーションツールであるため、完全なマスタリングパッケージ(Auphonicなど)やテキストベースの編集(Descriptなど)を提供しません。統合ポストプロダクションソリューションというよりも、専門的な「クリーンアップモジュール」と見なされています。
最適な用途
-
Adobeの金属的なアーティファクトなしで、音声が可能な限り現実的で人間的に聞こえる必要があるオーディオを保存する必要がある場合
-
ただし、音量レベルの不整合(ピーク)に対処する準備をし、極端なノイズ環境では分離が100%静かではない可能性があることを受け入れる必要があります
Riverside.fm
Riverside.fmは、高品質リモート録音の主要プラットフォームの1つとして広く認識されています。純粋なオーディオ強化ツールとは区別され、ソースキャプチャとAIを活用した編集機能を組み合わせたソリューションです。
最も印象的だったのは、録音の瞬間からオーディオとビデオがプロフェッショナルに聞こえることを保証する能力です。
優れている点: 最大の利点は、各参加者のデバイスでのローカル録音です。これにより、セッション中の障害やインターネットの不安定性に関係なく、フル解像度(ビデオで最大4K、オーディオでWAV)のファイルが保証されます。
ツールには、AIを活用した分離と自動クリーンアップを備えたMagic Audio機能が含まれています。これにより、音声の明瞭度に「残酷な違い」が生じ、多くの手動ポストプロダクションの必要性がなくなります。
Riversideは、長いエピソードをソーシャルメディア(TikTok、Reels)用の「ショート」に自動的に変換し、AIを通じてショーノート、タイトル、最適化された説明を生成します。
Descriptと同様に、Riversideは話者の視線を調整して、常にカメラを直接見ているように見えるAI機能を導入しました。これはビデオ品質にとって「ゲームチェンジャー」です。
自動転写から文を削除するだけで、オーディオとビデオを編集できます。多くの場合、Riversideの転写はDescriptの転写よりも優れていることがわかりました。
サービスには「トップノッチ」のカスタマーサポートと、クリエーターが改善と提案を共有する活発なFacebookコミュニティがあります。
苦労する点
-
まれですが、録音の完全な損失やセッション中の頻繁な切断の報告を聞いたことがあります。
-
テキストエディターは、従来の編集ツールと比較して不正確に感じられます。単語間の非常にタイトな遷移を処理することに失敗し、音声「痕跡」を残す可能性があります。
-
他のAIツールと同様に、モデルは主にフラットなアメリカのアクセントで訓練されたように見えます。これにより、より密なアクセント(オーストラリアなど)で困難が生じ、突然のオーディオカットが発生します。
-
最終ファイルのエクスポートとAI転写の処理は遅い可能性があり、特に長時間のプロジェクトで。
-
月額15〜19ドルから始まるプランでは、プロフェッショナルにまたは定期的にコンテンツを制作しない人にとってコストが高いです。
-
一部は直感的に感じますが、内部エディターインターフェースは不格好で、最初に習得するのが困難に感じられます。
最適な用途
-
画像と音質が優先事項であるリモートインタビューベースのポッドキャスト
-
私はそれを「キャプチャステーション」として使用しますが、多くのプロフェッショナルは最終編集のために生ファイル(WAV/MP4)をDaVinci ResolveやAdobe Premiere Proなどのソフトウェアにエクスポートすることを好みます。これにより、RiversideのWebエディターの制限を回避します
-
要約すると、それは「無類の録音」ツールですが、専用ソフトウェアの成熟に到達しようとしているエディターがあります
Podsqueeze
Podsqueezeは、単純なオーディオ処理を超えたAIを活用したポッドキャスト制作プラットフォームとして提示されています。音質改善からマーケティングとソーシャルメディアのためのコンテンツ作成まで、完全なワークフロー自動化に焦点を当てています。
優れている点: Auphonicと同様に、Podsqueezeは元の音声が忠実である限り、激しい背景ノイズ、顕著な残響、音量の不均衡を非常にうまく処理します。これには以下で作られた録音が含まれます:
- 通常のマイク
- 不完全な家庭環境
- 電話によってキャプチャされたオーディオ
複数の話者を含むシナリオで特に強力で、エピソード全体を通じて一貫した理解可能な音量を保証します。参加者間で録音条件が異なる場合でも機能します。
強化されたオーディオは、積極的な再合成に頼ることなく、音声の人間の音色を保持します。これにより、他のAIツールで一般的な金属的なアーティファクト、ロボット音声、または「デジタル」エフェクトを回避します。
孤立したオーディオ強化ツールとは異なり、Podsqueezeのオーディオ強化ツールは、ポッドキャスティング専用に設計されたエコシステムの一部です。以下と統合されています:
- 転写機能
- テキストベースの編集
- コンテンツの再利用
オーディオ改善は完全に自動で、エピソード間で一貫した結果を生み出します。技術パラメータを微調整したり、オーディオエンジニアリングの決定を下したりする必要はありません。
転写から直接単語を削除することでオーディオを編集できます。これは従来の波形編集と比較して大きな時間節約です。
長いエピソードからTikTok、Reels、YouTube Shorts用の短いクリップを自動的に生成する能力で際立っています。これにより、ポッドキャストコンテンツの配布と再利用が容易になります。
複数のショーを管理する機能を提供し、ショーごとに特定の設定でフォルダー内の複数のポッドキャストを整理できます。これにより、複数のショーやクライアントの管理が簡素化されます。
Podsqueezeは、複雑な技術的ワークフローなしで良好な結果を望むクリエーターにとって実用的で信頼性の高いソリューションです。
苦労する点
-
Podsqueezeは、高度に劣化または圧縮された音声を再構築するために示されていません。例には、電話通話録音や深刻なスペクトル情報損失のあるオーディオが含まれます。これらの場合、音声再合成ツールがより「劇的な」結果を生み出す可能性があります。
-
焦点は最終結果にあり、技術パラメータの手動微調整にはありません。これは、各処理ステップで外科的コントロールを求めるオーディオエンジニアを制限する可能性があります。
-
オーディオ強化ツールは技術的に堅牢ですが、その最大の価値は、完全なポッドキャスト制作と再利用ワークフロー内で使用されたときに現れます。
-
転写、編集、または再利用に興味がなく、時折のオーディオファイルを改善する必要があるだけの場合、オーディオ強化に排他的に焦点を当てたツールがよりシンプルで直接的な選択肢である可能性があります。
最適な用途
ポッドキャスターまたは繰り返しのオーディオコンテンツクリエーター、以下で:
- 録音にエコーや深刻な背景ノイズがあっても忠実な音声がある場合
- 複数の話者と一貫性のない音量があるインタビューがある場合
- エピソードをクリップやソーシャルメディアに再利用することに興味がある場合
目標が単に孤立したオーディオファイルを迅速に改善することであるクリエーターにとって、オーディオ強化に排他的に焦点を当てたよりシンプルなソリューションがより理にかなっている可能性があります。
しかし、統合された、一貫した、効率的なワークフローを求めるポッドキャスターにとって、Podsqueezeはターゲットオーディエンスに適切に調整された堅実なソリューションとして際立っています。
LALAL.AI
LALAL.AIは、ステム分離(楽器から音声を分割)の専門化から始まり、ノイズとエコー除去機能を備えた完全なオーディオ処理プラットフォームに進化したツールとして広く認識されています。
優れている点: オーディオ分離を作成するための「異常に強力な」ツールです。他のツールが失敗する状況で背景音楽から音声を分離することができます。
LALAL.AIが「真に困難な」または劣化したオーディオを扱う際に、iZotope RXパッケージ(業界標準)を上回ることがわかりました。
「盗まれた」素材や著作権保護された音楽を持つ外部ソースから取得した対話を抽出する必要がある場合のツールの選択です。
ステレオで既にミックスされたコマーシャルから音楽を除去するためにツールを使用しました。これにより、クリーンな音声を持つ新しいプレゼンテーション素材(シズルリール)の作成が可能になります。
Webインターフェースは、複雑な設定なしでファイルアップロードと迅速な結果を可能にする、率直で使いやすいと見なされています。
硬直した月額サブスクリプションとは異なり、従量課金の支払いモデルを提供します。これは、時折オーディオをクリーンアップする必要があるだけのクリエーターにとって非常に魅力的です。
苦労する点
-
ツールがノイズや音楽をクリーンアップするために「過度に働く」必要がある場合、最終的なオーディオは耳障りで、金属的で、過度に圧縮される可能性があります。
-
音楽除去後、対話に微妙なエコーが残る可能性があることに気づきました。これには、結果を磨くために追加のツール(Premiereでの残響削減など)の使用が必要です。
-
私のテストでは、LALAL.AIが時々フレーズや単語の終わりをカットし、音声の流暢さを損なうことがありました。
-
プレビューを許可していますが、処理されたファイルのダウンロードには分パッケージの支払いが必要です。
-
直接の音声クリーンアップ比較では、LALAL.AIは最終品質と自然な音声の保持の点でAuphonicの下に落ちます。
最適な用途
-
不可能な状況から対話を抽出する必要がある編集者
-
除去が必要な著作権保護された音楽で作業するプロフェッショナル
-
他のツールが処理できないオーディオ分離の課題に直面している人
-
ただし、完璧には代償があります。他のツールが達成できない音声分離と引き換えに、有機的な忠実度の一部の損失に対処する準備をする必要があります
-
よく録音されたポッドキャストの日常的な仕上げのための最初の選択肢である必要はありませんが、**「不可能な救出のための秘密兵器」**です
意図によるクイック推奨事項
オーディオを改善する最高のツールを選ぶことは、特定のニーズとワークフローに依存します。以下は、一般的なシナリオに基づいたクイック推奨事項です:
AudioEnhancer.comを選ぶ場合: 技術的な複雑さなしで信頼性が高く、自然に聞こえるオーディオクリーンアップが必要な場合。録音条件が理想的ではなかったが元の音声が忠実で、シンプルなアップロード-処理-ダウンロードワークフローで迅速にスタジオ品質の結果を望む場合に最適です。
Adobe Podcast Enhance Speechを選ぶ場合: 恐ろしい環境から録音を救う必要がある、一貫性のない録音セットアップで作業している、または技術的知識なしで迅速な改善を望む場合。特に高品質のコンテンツ(オーディオブックなど)では、AI処理されたオーディオが「非人間的」に聞こえるために拒否される可能性があるため、主要な制作方法ではなく緊急事態に理想的です。
Auphonicを選ぶ場合: 元の録音がすでに合理的で、自然な音声ダイナミクスを保持するプロフェッショナルで誠実な音を望む場合。一貫した音量が必要な複数の話者、同一の音響署名を望む週次エピソードプロデューサー、Adobe Podcastが過度に人工的であると感じる人に最適です。
Cleanvoice AIを選ぶ場合: 口頭の癖、頻繁な躊躇、または長いエピソードで手動で編集することが不可能な顕著な口の音がある場合。合成的/ロボット的な音を嫌い、より大きな忠実度と引き換えに背景ノイズが完全に除去されない可能性があることを受け入れて、元の音声テクスチャを維持することを好む場合に理想的です。
Descript Studio Soundを選ぶ場合: 速度を重視し、すでにマルチカメラビデオ編集や転写にプラットフォームを使用している場合。非アメリカのアクセントで作業している場合、または最大の音響忠実度が必要な場合は注意してください。絶対的な清潔さのために自然さを犠牲にする可能性があります。
DaVinci Resolve Voice Isolationを選ぶ場合: 編集環境を離れることなくプロフェッショナルなオーディオクリーンアップを望むビデオエディターである場合。Studioライセンスが必要ですが、高価な専用ソフトウェアに匹敵するワンノブのシンプルさを提供します。
Krispを選ぶ場合: ライブ通話、ストリーミング、またはリモート作業のためのリアルタイムノイズ抑制が必要な場合。最大の忠実度を要求するプロフェッショナルな録音では注意して使用してください。音声品質を劣化させる可能性があります。
Eleven Labs Voice Isolatorを選ぶ場合: Adobeの金属的なアーティファクトなしで、音声が可能な限り現実的で人間的に聞こえる必要があるオーディオを保存する必要がある場合。音量の不整合に対処する準備をし、極端なノイズ環境では分離が100%静かではない可能性があることを受け入れる必要があります。
Riverside.fmを選ぶ場合: 画像と音質が優先事項であるリモートインタビューポッドキャストを制作している場合。多くのプロフェッショナルは最終作業のために生ファイルを専用エディターにエクスポートし、主にキャプチャステーションとしてRiversideを使用します。
Podsqueezeを選ぶ場合: 転写、テキストベースの編集、コンテンツの再利用を含む統合ワークフローを望む繰り返しのポッドキャスターである場合。時折の孤立したオーディオファイルを改善する必要があるだけの場合、理想的ではありません。
LALAL.AIを選ぶ場合: 不可能な状況から対話を抽出する、著作権保護された音楽を除去する、または他のツールが処理できないオーディオ分離の課題に直面する必要がある場合。有機的な忠実度の一部を犠牲にする可能性がありますが、**「不可能な救出のための秘密兵器」**です。
結論
2026年にオーディオを改善する最高のツールは、音質を改善するための異なるアプローチを提供します。一部は積極的なAI再合成を使用して、最初からオーディオを再構築します。他のツールは、元の特性を保持する保守的な処理に焦点を当てます。一部はノイズ除去などの特定のタスクに優れ、他のツールは完全なワークフローを提供します。
鍵は、ツールをニーズに合わせることです。 深刻に損傷したオーディオで作業している場合、Adobe PodcastやLALAL.AIのようなツールが奇跡を実行できます。ロボット的なアーティファクトなしで自然な仕上げを望む場合、AuphonicやPodsqueezeがより良いバランスを提供します。リアルタイムシナリオでは、Krispがリードします。統合ビデオワークフローでは、DaVinci ResolveやRiverside.fmが優れています。
多くのプロフェッショナルは、ワークフローで複数のツールを使用し、それぞれが最適に機能する場所に適用します。最も重要な要因は、単一の「最高」のツールを見つけることではなく、各ツールが何をうまく行うか、いつ使用するかを理解することです。
最大の痛みのポイントから始め、実際の録音でいくつかのオプションをテストし、そこからツールキットを構築してください。