Die besten Tools zur Audio-Verbesserung und Studio-Klangqualität 2026
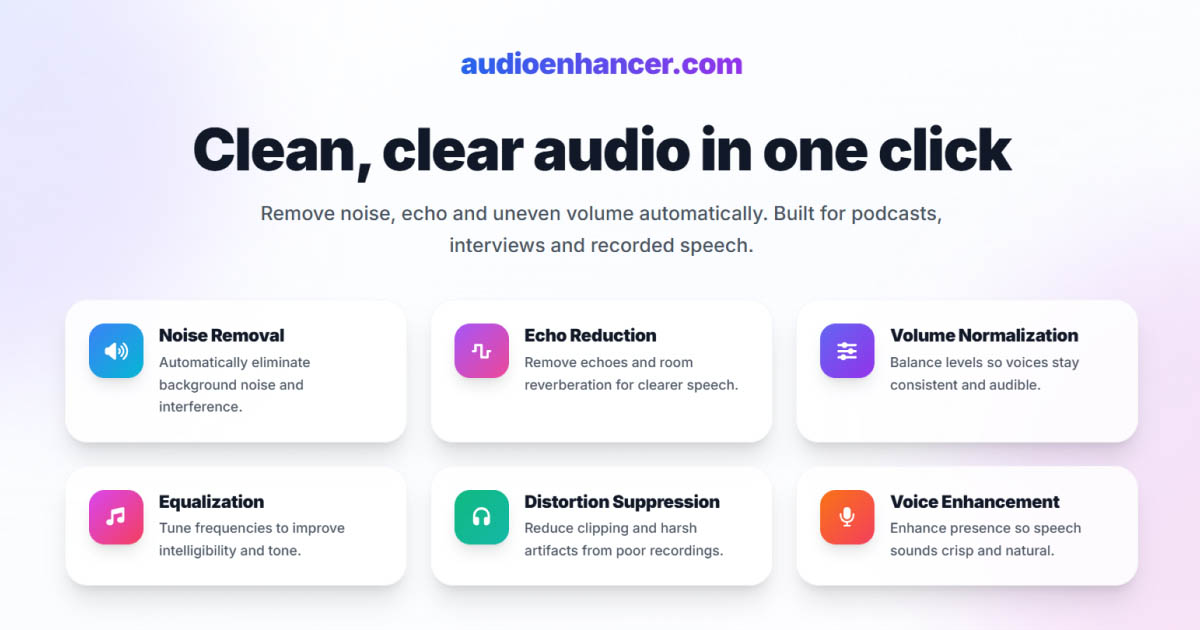

2026 ist professionelle Audioqualität zugänglicher als je zuvor. Ob du Podcasts von zu Hause aufnimmst, Feldinterviews bereinigst oder Voiceovers polierst, das richtige Verbesserungstool kann mittelmäßige Aufnahmen in Studio-Level-Klang verwandeln.
Die Herausforderung liegt nicht darin, Tools zu finden, die funktionieren, sondern dasjenige zu wählen, das zu deinem Workflow, Budget und Qualitätserwartungen passt.
Dieser Leitfaden untersucht die führenden Audio-Verbesserungstools, die heute verfügbar sind. Jedes Tool nimmt einen anderen Ansatz zur Verbesserung der Klangqualität. Einige verwenden aggressive KI-Stimmresynthese, um Audio von Grund auf neu aufzubauen. Andere konzentrieren sich auf konservative Verarbeitung, die den ursprünglichen Charakter deiner Stimme bewahrt.
Einige glänzen bei der Rauschunterdrückung, während andere sich auf Pegelung, Mastering oder Entfernung verbaler Tics spezialisieren.
Das beste Tool für dich hängt davon ab, womit du arbeitest und was du erreichen musst. Unten werden wir die Stärken, Einschränkungen und idealen Anwendungsfälle jedes Tools erkunden. Am Ende findest du schnelle Empfehlungen basierend auf häufigen Szenarien und Absichten.
AudioEnhancer.com
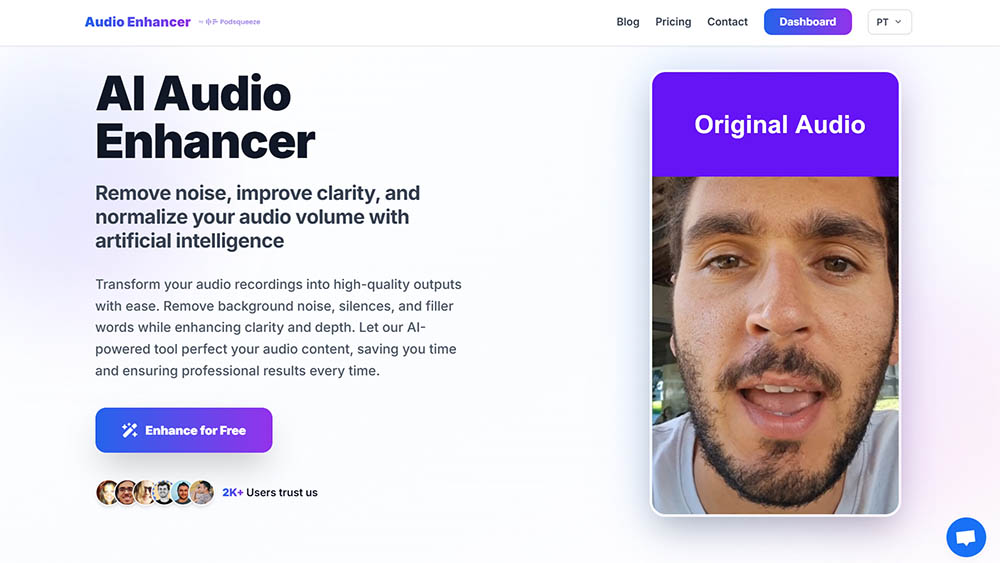
AudioEnhancer.com ist eine KI-gestützte Audio- und Video-Verbesserungsplattform, die darauf ausgelegt ist, Klang schnell und direkt zu bereinigen, auszugleichen und zu professionalisieren. Der Fokus liegt auf einem einfachen Ablauf: hochladen, verarbeiten und herunterladen, ohne unnötige Funktionen oder technische Komplexität.
Was es gut macht: Ich fand, dass es sehr gut mit schwerem Hintergrundgeräusch, intensivem Nachhall, Clipping, Plosiven und großen Lautstärke-Ungleichgewichten umgeht, solange die ursprüngliche Stimme treu ist. Es funktioniert konsistent mit Aufnahmen, die gemacht wurden mit:
- Dedizierten Mikrofonen
- Tragbaren Rekordern
- Telefonmikrofonen
Die Verarbeitung priorisiert die Bewahrung menschlichen Klangfarbes, vermeidet roboterhafte Stimmen, metallischen Klang oder digitale Artefakte, die bei aggressiven Resynthese-Ansätzen üblich sind.
Es ist besonders effektiv bei Content mit mehreren Sprechern und sorgt für konsistente und verständliche Pegel während der gesamten Aufnahme.
Der exklusive Fokus auf Eingabe → Verarbeitung → Download macht das Tool ideal, wenn du sofortige Ergebnisse benötigst, ohne komplexe Dashboards oder lange Workflows.
Es unterstützt sowohl Audio- als auch Videodateien, was es nützlich für Content macht, der für YouTube, Social Media, Video-Interviews oder UGC bestimmt ist.
Das Dashboard ist minimalistisch und einfach zu verwenden, für Benutzer konzipiert, die ein spezifisches Problem ohne Lernkurve lösen wollen.
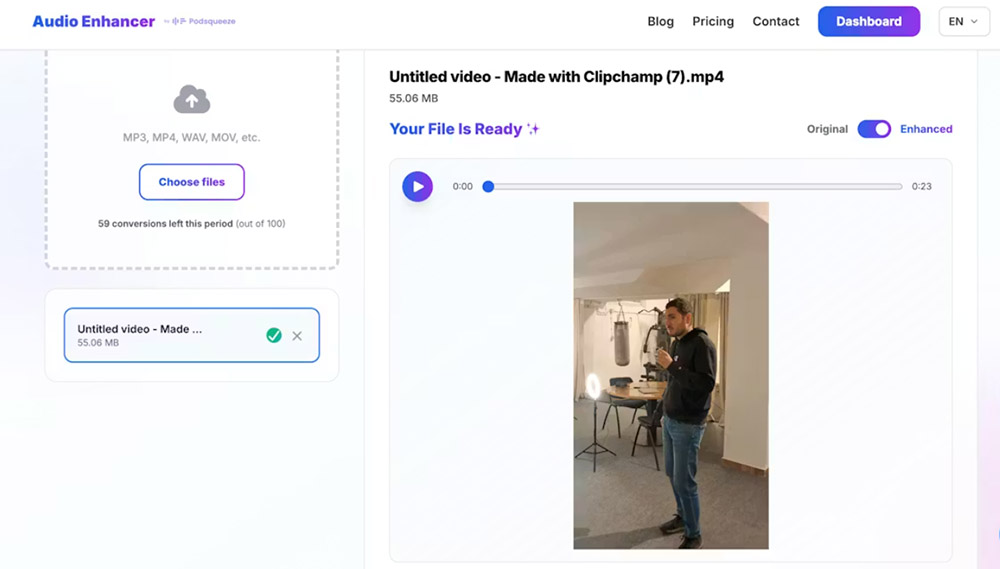
Das vorhersehbare und konsistente Verhalten macht das Tool geeignet für wiederkehrende Nutzung durch Ersteller und Profis, die Stabilität und Natürlichkeit schätzen.
Wo es Schwierigkeiten hat
-
AudioEnhancer.com ist nicht die beste Option für die Rekonstruktion stark degradierter oder komprimierter Stimmen. Beispiele sind Telefonanruf-Aufnahmen oder Audio mit schwerem spektralen Informationsverlust.
-
Das Tool ist ergebnisorientiert und bietet keine detaillierte manuelle Feinabstimmung von Parametern. Dies kann fortgeschrittene Audio-Engineering-Benutzer einschränken.
-
Es konzentriert sich ausschließlich auf Klangverbesserung. Es enthält keine Bearbeitungs-, Transkriptions- oder Content-Wiederverwendungsfunktionen, die in anderen Workflows zusätzliche Tools erfordern können.
Am besten für
AudioEnhancer.com ist ein extrem zuverlässiges Tool zum Bereinigen und Professionalisieren von Audio und Video unter realen Aufnahmebedingungen.
Es wird besonders empfohlen, wenn:
- Aufnahmebedingungen nicht ideal waren (Echo, Rauschen, Clipping)
- Das Ziel ist, schnell Studio-Klang zu bekommen
- Die Priorität ist Einfachheit, Vorhersehbarkeit und Natürlichkeit
Es ist kein Tool für "künstliche Wunder", sondern ein robustes und stabiles Audio-Bereinigungstool, konzipiert für Content-Ersteller und Profis, die konsistente und natürliche Ergebnisse ohne technische Reibung benötigen.
Adobe Podcast Enhance Speech
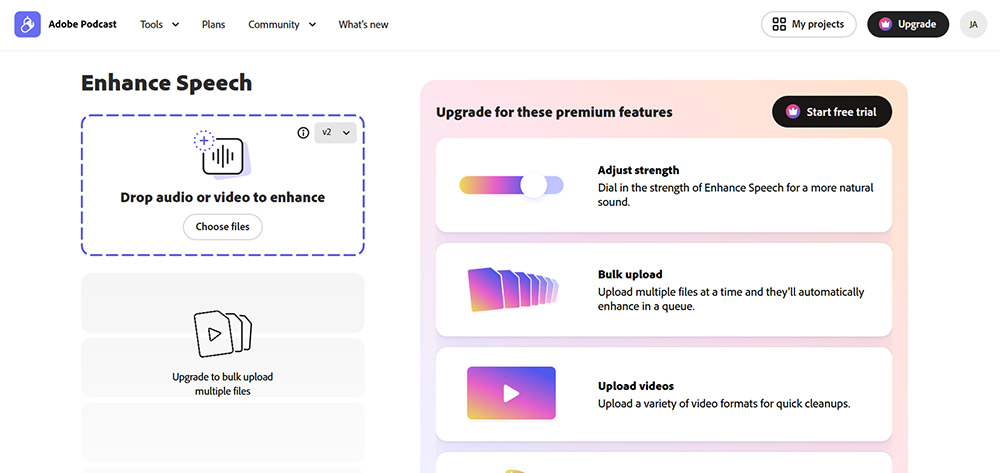
Adobe Podcast Enhance Speech (früher Project Shasta) ist ein browserbasiertes Tool, das Deep-Learning-Modelle verwendet, um Aufnahmen von niedriger Qualität in Audio zu verwandeln, das klingt, als wäre es in einem professionellen Studio aufgenommen worden.
Die Technologie basiert auf Stimmresynthese, bei der die KI nicht nur Rauschen filtert, sondern eine neue Stimme generiert, die das Klangfarbe des ursprünglichen Sprechers nachahmt.
Was es gut macht: Ich fand es wirklich beeindruckend für die Wiederherstellung von Audio, das in unmöglichen Umgebungen aufgenommen wurde. Dies umfasst:
- Laute Kongresshallen
- Hotels mit instabilem Wi-Fi
- Belebte Straßen mit starkem Verkehr
Es glänzt beim Entfernen spezifischer Arten von Rauschen, einschließlich Wind, Industrielüfter, Staubsauger, Baumaschinen und Hintergrundmusik. Das Tool kann den Hauptsprecher isolieren, auch wenn andere Stimmen überlappen.
Es ist überraschend effektiv beim Reparieren von geclipptem Audio, das unter Mikrofon-Gain-Überlastung gelitten hat. Die Benutzeroberfläche ist Drag-and-Drop einfach mit null Lernkurve.
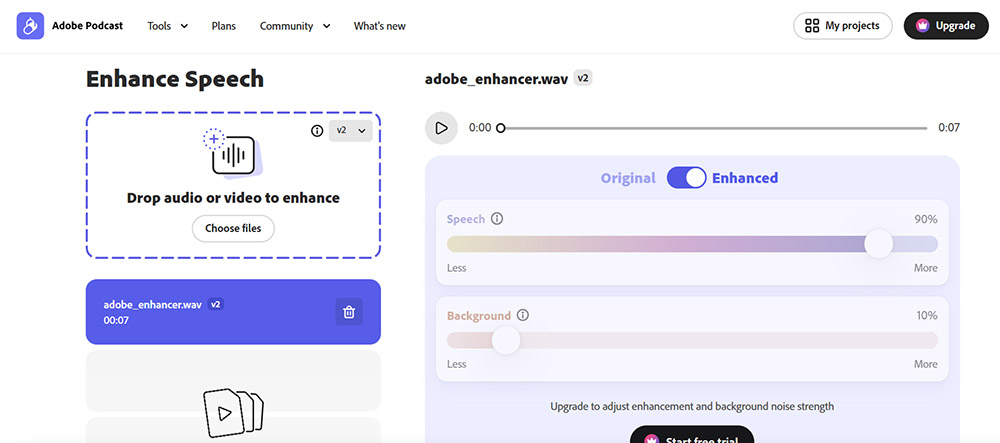
Es funktioniert besonders gut mit AirPods-Aufnahmen aufgrund des konstanten Abstands zwischen Mikrofon und Mund. Es kann ein 20€-Mikrofon wie ein 100€-Mikrofon klingen lassen.
Wo es Schwierigkeiten hat
-
Die gleiche Resynthese-Technologie, die Wunder ermöglicht, kann versagen und Stimmen metallisch, roboterhaft oder seltsam komprimiert klingen lassen. Dies passiert besonders in Version V2 oder wenn das ursprüngliche Rauschen zu dicht ist.
-
Unter extremen Rauschbedingungen kann die KI Phoneme oder Wörter erfinden, die der Sprecher nie gesagt hat. Es kann sogar zufällige Stimmen in die finale Datei mischen.
-
Die Web-Version ist deutlich überlegen gegenüber der Premiere Pro-Integration, die begrenzt ist, um Benutzer-Hardware nicht zu blockieren. Dies zwingt viele Profis zu konstanten Round-Trip-Workflows.
-
Es ist nicht geeignet für Musik oder komplexe Klanglandschaften, bei denen du Ambiance bewahren willst. Das Tool versucht, alles zu bereinigen, was nicht menschliche Sprache ist, was künstlerische Absicht ruinieren kann.
-
Die kostenlose Version bietet keine Einstellungen zum Anpassen, was dich dem automatischen Ergebnis ausliefert.
Am besten für
-
Content-Ersteller, die Aufnahmen aus schlechten Umgebungen retten müssen
-
Podcaster, die mit inkonsistenten Aufnahme-Setups arbeiten
-
Jeder, der schnelle Verbesserungen ohne technisches Wissen benötigt
Ich fand, dass der Sweet Spot darin liegt, den Intensitäts-Schieberegler (verfügbar im Premium) auf etwa 70–75% einzustellen für den natürlichsten Klang. Alternativ funktioniert die Vorverarbeitung von Audio mit leichter Rauschunterdrückung, bevor Adobes Verbesserer bei 20–40% angewendet wird, gut für finale Politur.
Auphonic
Auphonic ist ein cloudbasiertes Audio-Post-Production-Service, das unter einer Philosophie der "natürlichen Politur" arbeitet. Im Gegensatz zu Tools wie Adobe Podcast, die aggressive Stimmresynthese verwenden, konzentriert sich Auphonic auf technische Optimierung der ursprünglichen Aufnahme.
Es wird weithin als "Goldstandard für automatisches Mastering" unter Podcasting-Veteranen angesehen. Beim Vergleichen von Auphonic vs Adobe werden die Unterschiede in technischer Kontrolle versus aggressive Resynthese klar.
Was es gut macht: Der Intelligent Leveler ist die am meisten gefeierte Funktion. Die KI analysiert Dateien und gleicht automatisch Pegel zwischen verschiedenen Sprechern, Musik und Soundeffekten aus. Dies eliminiert die Notwendigkeit komplexer manueller Kompressoren.
Es ist das Go-to-Tool, um sicherzustellen, dass Audio Plattform-Loudness-Standards erfüllt. Dies umfasst -14 LUFS für YouTube oder -16 LUFS für Podcasts und verhindert, dass Audio zu leise oder verzerrt klingt.
Die Crossgate-Funktion wird für Aufnahmen mit mehreren Mikrofonen im selben Raum hoch gelobt. Sie reduziert drastisch Mikrofon-Bleeding, wenn die Stimme einer Person vom Mikrofon einer anderen erfasst wird.
Der Atem-Entfernungsalgorithmus gilt als einer der wenigen auf dem Markt, der gut genug funktioniert, um Stunden manueller Bearbeitung zu sparen. Es entfernt auch effektiv Mundklicks und unangenehme Stillephasen.
Bandbreiten-Erweiterung kann Leben zu gedämpften oder niedrigwertigen Aufnahmen zurückbringen, indem Frequenzen wiederhergestellt werden, die verloren schienen.
Ein einzigartiger Vorteil ist, dass Auphonic keine zusätzlichen Credits berechnet, wenn du dich entscheidest, Einstellungen an einer bereits verarbeiteten Datei zu ändern und die Produktion erneut auszuführen.
Es bietet einen "Set-and-Forget"-Workflow mit Unterstützung für:
- Metadaten
- Automatische Show-Notizen
- Kapitel
- Transkription via Whisper in mehreren Sprachen
Wo es Schwierigkeiten hat
-
Auphonic ist kein "Wunder-Resynthese"-Tool wie Adobe. Wenn das ursprüngliche Audio extrem aggressives Hintergrundgeräusch oder Nachhall hat, kann Auphonic die Stimme möglicherweise nicht so gut isolieren wie neuere generative Modelle.
-
Das Web-Plattform-Design wirkt veraltet im Vergleich zu modernen 2025-Visualstandards.
-
Obwohl es viele Parameter bietet, sind einige Funktionen verknüpft. Zum Beispiel ist der DeBreath-Algorithmus manchmal an den Rauschreduzierer gebunden, was unabhängige Anpassung der Atemreduktionspegel versus Breitbandrauschen verhindert.
-
Die kostenlose Version (die 2 Stunden pro Monat bietet) fügt ein kleines Audio-Jingle am Anfang oder Ende verarbeiteter Produktionen hinzu.
-
Während es Musik in bestimmten Einstellungen gut handhabt, ist seine Hauptstärke Dialog. Es ist möglicherweise nicht ideal für reines Musik-Mastering.
Am besten für
Podcaster, die professionellen, ehrlichen Klang wollen, der natürliche Stimmdynamik bewahrt, ohne wie ein KI-Roboter zu klingen. Es ist ideal, wenn:
- Die ursprüngliche Aufnahme bereits vernünftig ist
- Es mehrere Sprecher gibt, die konsistente Lautstärke benötigen
- Ersteller wöchentliche Episoden produzieren und identische klangliche Signaturen über alle Inhalte hinweg wollen
Wenn du Adobe Podcast zu künstlich findest oder metallische Artefakte bemerkst, bietet Auphonic das perfekte Gleichgewicht.
Cleanvoice AI
Cleanvoice AI ist ein cloudbasiertes Post-Production-Tool, das sich durch seinen Fokus auf mikroakustische Probleme und verbale Tics unterscheidet. Im Gegensatz zu Tools, die nur Umgebungsgeräusch reduzieren, ist Cleanvoice speziell darauf trainiert, biologische Elemente und Zögern zu identifizieren und zu entfernen, die Podcast-Hören ermüdend machen.
Was es gut macht: Es ist hochwirksam beim automatischen Erkennen von Füllwörtern wie "ähm", "ah" und "wie" in mehr als 20 Sprachen.
Es wird als "chirurgischer" beschrieben als Konkurrenten wie Descript beim Eliminieren von:
- Mundgeräuschen
- Klicks
- Lippenschmatzen
- Schwerem Atmen
Eine seiner größten Stärken ist, dass es das ursprüngliche Stimmklangfarbe nicht so aggressiv verändert wie Adobe Podcast. Es bewahrt die natürliche Kadenz der Sprache und entfernt nur Ablenkungen. Der CleanVoice vs Adobe Vergleich zeigt, wie jedes Tool verschiedene Rauschszenarien handhabt.
Anstatt automatische destruktive Änderungen anzuwenden, präsentiert dir Cleanvoice eine Timeline von Vorschlägen. Dies ermöglicht es dir, Bearbeitungen individuell zu akzeptieren oder abzulehnen.
Es identifiziert und entfernt effizient "tote Luft" (verlängerte Stillephasen) und verbessert Content-Rhythmus ohne manuelle Anstrengung.
Wo es Schwierigkeiten hat
-
Wenn es mit erheblichem Hintergrundgeräusch oder sehr lauten Umgebungen konfrontiert wird, kann das verarbeitete Audio beginnen, "pixelig", "zerknittert" oder mit einem seltsamen Autotune-Effekt zu klingen.
-
Trotz Transkriptionsdiensten fand ich die Ergebnisse enttäuschend. Kostenlose Software wie Audacity erzielt in diesem spezifischen Bereich überlegene Ergebnisse.
-
Es ist ein Audio-Bereinigungstool, kein vollständiger Editor. Es fehlen robuste Video-Bearbeitungsfunktionen oder Echtzeit-Verarbeitungsfähigkeiten.
-
Das Preismodell basierend auf Verarbeitungsstunden (z.B. 11€ für 10 Stunden) kann teuer werden, wenn du große Content-Volumen produzierst.
-
Obwohl es Rauschen entfernt, ist es weniger effektiv als Adobe oder iZotope RX beim Handhaben von Nachhall in großen Räumen. In einigen Fällen bevorzugte ich das Original-Audio gegenüber einem "pixligen" Ergebnis.
Am besten für
-
Podcaster mit verbalen Tics
-
Ersteller, die häufig zögern oder prominente Mundgeräusche haben, die in langen Episoden unmöglich manuell zu bearbeiten wären
-
Wenn du den synthetischen/roboterhaften Klang von Adobe hasst und die ursprüngliche Textur deiner Stimme beibehalten möchtest. Du musst akzeptieren, dass Hintergrundgeräusch möglicherweise nicht vollständig eliminiert wird, im Austausch für größere Wiedergabetreue
-
Editoren, die wollen, dass KI die schwere Arbeit des Findens von Fehlern macht, aber das letzte Wort darüber haben wollen, was durch das Vorschlagssystem geschnitten wird
Descript Studio Sound
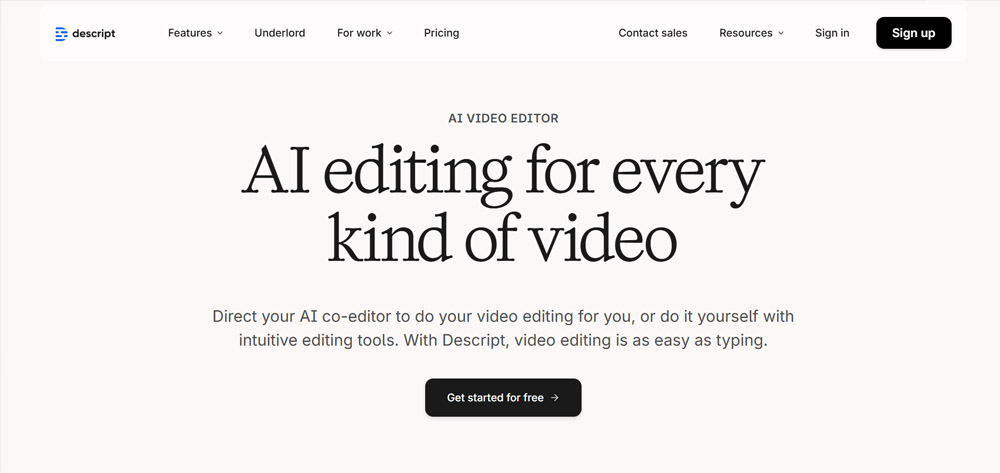
Descript Studio Sound ist nicht nur ein einfacher Audio-Prozessor, sondern eine zentrale Funktion innerhalb eines All-in-One-Bearbeitungs-Ökosystems, das Produktivität durch textbasierte Bearbeitung neu definiert.
Ich war beeindruckt von seiner Effizienz, obwohl ich einige spezifische Kritiken an der verarbeiteten Klangtextur habe.
Was es gut macht: Der größte Vorteil ist Studio Sounds Integration in einen Workflow, in dem du Audio bearbeitest, als wäre es ein Textdokument.
Die Fähigkeit, Hintergrundgeräusch, Echo und Nachhall mit einem Klick zu entfernen, während gleichzeitig Füllwörter ("ähm" und "ah") und Stillephasen eliminiert werden, gilt als unschlagbare Lösung für Produktionsgeschwindigkeit. Der Descript vs Adobe Vergleich hebt hervor, wie Workflow-Unterschiede die reale Nutzung beeinflussen.
In meinen Tests überraschte mich Descript, indem es Audio von "schlecht zu gut" und "gut zu ausgezeichnet" transformierte. Ich würde es 8/10 für Klarheit und seine Fähigkeit bewerten, mittelmäßige Aufnahmen für professionellen Content brauchbar zu machen.
Das Tool kann Audio wiederherstellen, das unter erbärmlichen Bedingungen aufgenommen wurde, wie durch "Blechdosen" oder alte Telefone, und es hörbar und sauber machen.
Über reine Audio-Verbesserung hinaus bietet Descript Tools wie Overdub (Stimmklonierung, um Fehler ohne Neuaufnahme zu reparieren) und KI-gestützte Blickkontakt-Anpassung. Diese ergänzen die Video- und Podcast-Erstellungserfahrung.
Im Gegensatz zu einigen automatischen Tools erlaubt Descript, die Studio Sound-Effektintensität durch einen Schieberegler anzupassen. Dies gibt dir die Freiheit, das Gleichgewicht zwischen totaler Sauberkeit und Natürlichkeit zu finden.
Wo es Schwierigkeiten hat
-
Eine wiederkehrende Kritik ist, dass Studio Sound einen "metallischen" oder "roboterhaften" Klang erzeugen kann. Dies passiert besonders, wenn der Algorithmus gezwungen wird, Dateien mit schwerem Rauschen zu verarbeiten oder wenn er mit maximaler Intensität angewendet wird.
-
Ich bemerkte, dass die KI kämpft, wenn sie Akzente verarbeitet, bei denen Wörter zusammenfließen. Dies führt zu abrupten Schnitten, Audio-"Sprüngen" oder unerwünschtem digitalem Stottern.
-
Obwohl die Stimmklonierungsfunktion technisch beeindruckend ist, kann die generierte Stimme emotionslos oder "tot" klingen. Dies erfordert ständige menschliche Überwachung, um einen übermäßig synthetischen Ton zu vermeiden.
-
Im Gegensatz zu 100% Cloud-Tools (wie Adobe) verwendet Descript die Verarbeitungsleistung deines Computers. Dies bedeutet, dass Tool-Leistung und Anwendungsgeschwindigkeit direkt von deiner verfügbaren Hardware abhängen.
-
Der Export- und Veröffentlichungsprozess fühlt sich seltsam und manchmal langsam an, besonders im Vergleich zu einfachen Web-Tools.
-
Die professionelle Plan-Abonnement (etwa 35 USD/Monat) ist für gelegentliche oder unabhängige Ersteller prohibitiv. Du könntest am Ende kostenlose oder Pay-per-Use-Alternativen suchen.
Am besten für
-
Produktionsteams, die Geschwindigkeit schätzen und die Plattform bereits für Multi-Kamera-Video-Bearbeitung oder Transkription verwenden
-
Wenn du jedoch maximale akustische Wiedergabetreue suchst oder mit nicht-amerikanischen Akzenten arbeitest, höre sorgfältig auf Ergebnisse. Das Tool kann Natürlichkeit zugunsten absoluter Sauberkeit opfern
-
Es wird als Tool gesehen, das "Audio ein Facelift gibt", aber wenn es falsch verwendet wird, kann es das "Herz" und die Emotion aus menschlicher Sprache entfernen
DaVinci Resolve Voice Isolation
DaVinci Resolve Voice Isolation ist ein revolutionäres Tool, das professionelle Audio-Wiederherstellungsfähigkeiten direkt in den Video-Bearbeitungs-Workflow brachte. Ich fand seine Leistung vergleichbar mit dedizierter, teurer Software, obwohl es spezifische technische Einschränkungen gibt.
Was es gut macht: Die beeindruckendste Eigenschaft ist, dass es eine One-Knob-Lösung ist. Ich erzielte Ergebnisse, die überlegen oder gleichwertig zu iZotope RX Advanced (einem Industriestandard) waren, mit viel weniger Aufwand und manueller Anpassung.
Das Tool hat sich als fähig erwiesen, Stimmen in extrem lauten Umgebungen zu isolieren. Beispiele sind Interviews, die neben Düsentriebwerken oder in lauten Restaurants mit Hintergrundmusik und Tellergeklapper aufgenommen wurden.
Es ist besonders effektiv beim Entfernen konstanter Drohnen und weißem Rauschen, wie Motorengeräuschen, und macht Audio perfekt brauchbar.
Im Gegensatz zu Tools wie Adobe Podcast (Web-Version) ist Voice Isolation in die Software eingebaut. Dies eliminiert die Notwendigkeit, Dateien für Bereinigung zu exportieren und zu importieren.
Ich fand, dass das Tool weniger Artefakte einführt als andere KI-Lösungen und dabei eine natürlichere Stimme bewahrt, während es Rauschen entfernt.
Wo es Schwierigkeiten hat
-
Einer der am meisten kritisierten Punkte ist, dass die Funktion nicht in der kostenlosen Version von DaVinci Resolve verfügbar ist. Sie erfordert den Kauf der Studio-Lizenz.
-
Da die Verarbeitung in Echtzeit erfolgt, bemerkte ich, dass Audio während der Timeline-Vorschau "stecken bleiben" oder stottern kann. Dies passiert besonders in Videosegmenten, wo der Effekt angewendet wurde.
-
Wenn die Intensität zu hoch ist, kann die KI möglicherweise nicht zwischen Rauschen und nicht-sprachlichen menschlichen Ausdrücken unterscheiden. Dies kann dazu führen, dass Lachen, Schreie oder Seufzer geschnitten werden, was manuelle ADR erfordern kann.
-
Ich bemerkte, dass das Tool unerwünschte tonale oder Pitch-Änderungen in sehr kurzen Clips (wie Fahrzeugaufnahmen) einführt. Es versagt gelegentlich beim Verarbeiten von Rauschen oder schneidet Audio vollständig.
-
Als ich es mit spanischen Sprechern testete, waren die Ergebnisse schlecht. Dies deutet darauf hin, dass das KI-Modell möglicherweise hauptsächlich mit englischen Stimmen trainiert wurde.
Am besten für
-
Video-Editoren, die professionelle Audio-Bereinigung wollen, ohne ihre Bearbeitungsumgebung zu verlassen
-
Adobe Podcast Enhance ist immer noch leicht überlegen bei reiner Rauschunterdrückung, aber Resolve gewinnt für die Bequemlichkeit, in den Video-Editor integriert zu sein
-
Während RX chirurgische Kontrolle bietet (De-Click, De-Plosive usw.), ist Resolve besser für Geschwindigkeit bei reiner Dialogisolierung. Es fühlt sich wie "Magie" für seine Einfachheit an
-
Waves' Plugin bietet bessere Echtzeit-Leistung ohne Hardware-"Schluckauf", obwohl Resolves Isolierung Top-Level ist
Krisp
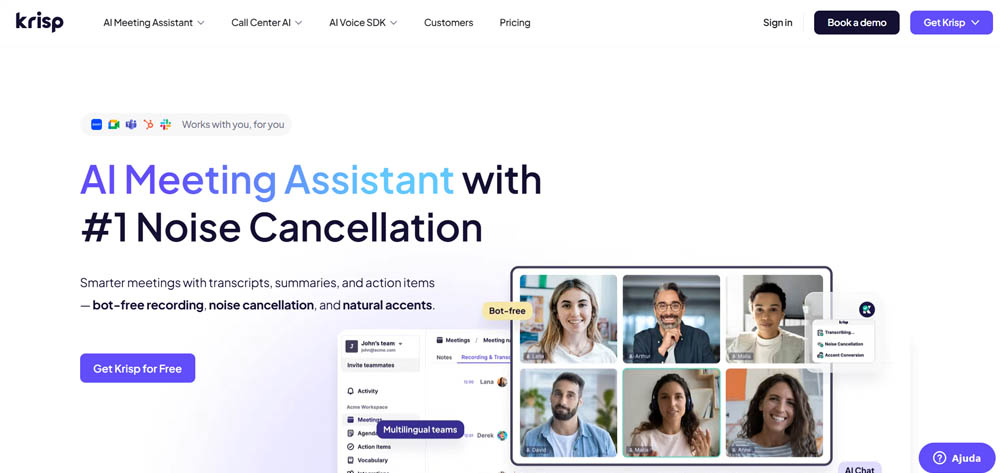
Krisp wird weithin als unbestrittener Führer in der Echtzeit-Audio-Verarbeitung anerkannt. Es unterscheidet sich von den meisten anderen Tools, die nur in der Post-Production arbeiten. Das Verstehen der Echtzeit vs. Post-Production Kompromisse hilft zu bestimmen, welcher Ansatz zu deinem Workflow passt.
Es fungiert als Schicht zwischen dem Mikrofon und der Aufnahme- oder Konferenzsoftware und verwendet KI, um Audio zu bereinigen, bevor es überhaupt aufgenommen wird.
Was es gut macht: Es ist ausgezeichnet beim sofortigen Entfernen unvorhersehbarer häuslicher und städtischer Geräusche. Beispiele sind lachende Kinder, bellende Hunde oder zuschlagende Türen.
Das Tool ist darauf ausgelegt, geringen CPU-Verbrauch zu haben und sicherzustellen, dass der Computer während Videoanrufen oder gleichzeitigen Streaming-Sitzungen keine Leistung verliert.
Es funktioniert mit mehr als 800 Anwendungen, einschließlich:
- Zoom
- Microsoft Teams
- Skype
- OBS
- DAWs wie Audacity
Zusätzlich zum Bereinigen deiner Stimme (Mikrofon) kann Krisp auch Audio bereinigen, das von anderen Teilnehmern im Anruf kommt (Lautsprecher), und eliminiert deren Hintergrundgeräusch.
Es enthält automatische Tools zum Generieren von Meeting-Notizen und unbegrenzten Transkriptionen und hilft, Stunden wöchentlicher Verwaltungsarbeit zu sparen.
Es bietet einen großzügigen kostenlosen Plan, der 60 Minuten Verarbeitung pro Tag bietet. Dies ist ausreichend für gelegentliche Ersteller und Profis in gelegentlichen Meetings.
Wo es Schwierigkeiten hat
-
Der Preis aggressiver Rauschunterdrückung ist Verschlechterung der Stimmwiedergabetreue. Verarbeitetes Audio kann "dünn" klingen, mit leichtem Echo oder einer "flachen" und roboterhaften Textur.
-
Als ich es in einer bereits ruhigen Umgebung mit einem hochwertigen Studiomikrofon testete, versuchte Krisp, "Rauschen zu finden, wo es nicht existierte". Dies ruinierte schließlich die Klarheit und natürliche Präsenz der Stimme.
-
Obwohl es eine Akzent-Lokalisierungs-/Konvertierungsfunktion bietet, sind die Ergebnisse enttäuschend. Sie klingen generisch und unnatürlich und schaffen es nicht, die Essenz der ursprünglichen Stimme einzufangen.
-
Als Tool, das Verifizierung erfordert, hat es begrenzte Offline-Funktionalität.
-
Der Übergang von lebenslangen Lizenzen zu einem monatlichen Abonnementmodell kann für diejenigen weniger attraktiv sein, die es nicht täglich verwenden.
Am besten für
-
Remote-Arbeiter, Streamer und alle, die Echtzeit-Stimmarbeit machen, die ihre Umgebung nicht kontrollieren können
-
Verwende es mit Vorsicht. Es ist legitim für Live-Übertragungen und Anrufe, aber für professionelle Aufnahmen, die "Audio-Nirvana" erfordern, ist es besser, "schmutzigen" Klang aufzunehmen und ihn später in der Post-Production mit mächtigeren Tools wie Descript oder Adobe zu verarbeiten. Dies vermeidet, dass die Stimme bereits an der Quelle zu verarbeitet klingt
Eleven Labs Voice Isolator
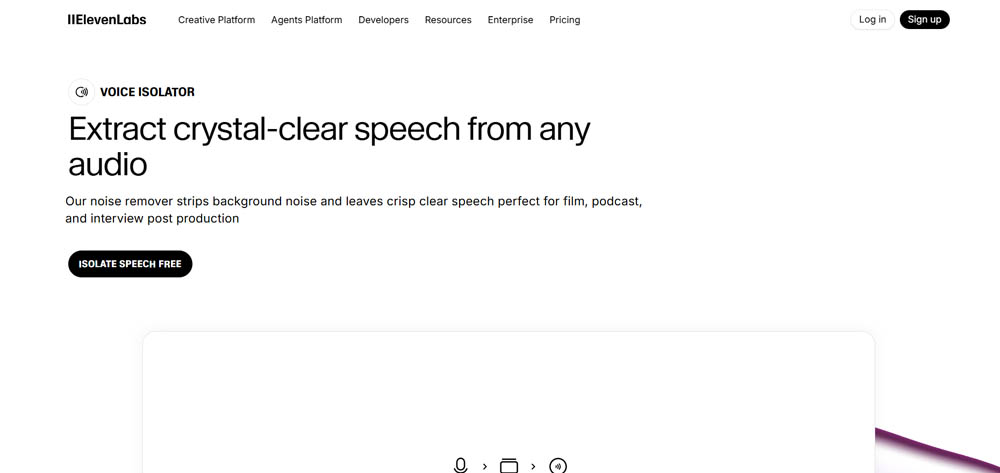
Eleven Labs Voice Isolator ist ein relativ neuer Start im KI-Audio-Verarbeitungsmarkt. Obwohl weniger debattiert als Adobe Podcast, sammelt es bereits starke und kontrastierende Meinungen in Experten-Communities. Der ElevenLabs vs Adobe Vergleich zeigt, wie jedes Tool Stimmisolierung unterschiedlich angeht.
Was es gut macht: Klangfarben-Bewahrung ist der größte Vorteil. Ich fand Eleven Labs überlegen gegenüber beiden Adobe-Versionen (Web und Premiere) für die Bewahrung des ursprünglichen Stimmklangfarbes.
Während andere Tools Stimmen aufgrund aggressiver Resynthese "synthetisch" klingen lassen können, bewahrt Eleven Labs organische Stimmidentität, während es entfernt, was drumherum ist.
Es ist hochwirksam beim "Abziehen" von allem, was nicht Sprache ist. Es ist perfekt, wenn du nur den Sprecher in Aufnahmen isolieren musst, wo die Stimme gut definiert ist, aber der Hintergrund chaotisch ist.
Wie seine direkten Konkurrenten konzentriert es sich auf eine vereinfachte Erfahrung und ermöglicht schnelle Ergebnisse ohne tiefes Audio-Engineering-Wissen.
Wo es Schwierigkeiten hat
-
Ein technisches Problem, das ich fand, ist, dass das Tool unerwünschte Audio-Peaks (Peaking) verursachen kann. Dies zwingt dich, Limiter oder manuelle Gain-Anpassungen nach der Verarbeitung anzuwenden, um Verzerrung zu vermeiden.
-
Im Gegensatz zu Tools wie Adobe Podcast, die manchmal "überbereinigen" (sogar Phoneme entfernen), lässt Eleven Labs' Isolator unter bestimmten Bedingungen noch etwas Hintergrundgeräusch durch. Es ist nicht so "unerbittlich" bei totaler Bereinigung, wie du vielleicht möchtest.
-
Weil es ein Isolations-Tool ist, bietet es nicht das komplette Mastering-Paket (wie Auphonic) oder textbasierte Bearbeitung (wie Descript). Es wird eher als spezialisiertes "Bereinigungsmodul" gesehen als als integrale Post-Production-Lösung.
Am besten für
-
Wenn du Audio retten musst, wo die Stimme so real und menschlich wie möglich klingen muss, ohne die metallischen Artefakte von Adobe
-
Du solltest jedoch darauf vorbereitet sein, mit einiger Inkonsistenz in Lautstärkepegeln (Peaks) umzugehen und akzeptieren, dass Isolierung möglicherweise nicht 100% still in extremen Rauschumgebungen ist
Riverside.fm
Riverside.fm wird weithin als eine der führenden Plattformen für hochwertige Remote-Aufnahme anerkannt. Es unterscheidet sich von reinen Audio-Verbesserungstools dadurch, dass es eine Lösung ist, die Quell-Erfassung mit KI-gestützten Bearbeitungsfähigkeiten kombiniert.
Was mich am meisten beeindruckte, ist seine Fähigkeit, sicherzustellen, dass Audio und Video bereits ab dem Moment der Aufnahme professionell klingen.
Was es gut macht: Der größte Vorteil ist lokale Aufnahme auf dem Gerät jedes Teilnehmers. Dies garantiert Dateien in voller Auflösung (bis zu 4K im Video und WAV im Audio), unabhängig von Ausfällen oder Internet-Instabilität während der Sitzung.
Das Tool enthält eine Magic Audio-Funktion mit KI-gestützter Isolierung und automatischer Bereinigung. Ich fand, dass dies einen "brutalen Unterschied" in der Stimmklarheit macht und die Notwendigkeit vieler manueller Post-Production eliminiert.
Riverside transformiert automatisch lange Episoden in "Shorts" für Social Media (TikTok, Reels) und generiert Show-Notizen, Titel und optimierte Beschreibungen via KI.
Ähnlich wie Descript führte Riverside eine KI-Funktion ein, die den Blick des Sprechers anpasst, sodass er immer direkt in die Kamera zu schauen scheint. Dies ist ein "Game Changer" für Videoqualität.
Es erlaubt, Audio und Video einfach zu bearbeiten, indem Sätze aus der automatischen Transkription gelöscht werden. Ich fand, dass Riversides Transkription in vielen Fällen überlegen zu Descripts ist.
Der Service hat "Top-Notch"-Kundensupport und eine aktive Facebook-Community, in der Ersteller Verbesserungen und Vorschläge teilen.
Wo es Schwierigkeiten hat
-
Obwohl selten, habe ich Berichte über totalen Verlust von Aufnahmen oder häufige Unterbrechungen während Sitzungen gehört.
-
Der Text-Editor fühlt sich unpräzise an im Vergleich zu traditionellen Bearbeitungstools. Es versagt beim Handhaben sehr enger Übergänge zwischen Wörtern, was Stimm-"Spuren" hinterlassen kann.
-
Wie andere KI-Tools scheint das Modell hauptsächlich mit flachen amerikanischen Akzenten trainiert worden zu sein. Dies präsentiert Schwierigkeiten mit dichteren Akzenten (wie australisch), was zu abrupten Audio-Schnitten führt.
-
Das Exportieren finaler Dateien und Verarbeiten von KI-Transkriptionen kann langsam sein, besonders in langdauernden Projekten.
-
Mit Plänen ab 15–19 $ monatlich ist die Kosten hoch für diejenigen, die nicht professionell oder regelmäßig Content produzieren.
-
Obwohl einige es intuitiv finden, fühlt sich die interne Editor-Benutzeroberfläche klobig und schwer zu meistern an.
Am besten für
-
Podcasts basierend auf Remote-Interviews, wo Bild- und Klangqualität Prioritäten sind
-
Ich verwende es als "Erfassungsstation", aber viele Profis bevorzugen es, rohe Dateien (WAV/MP4) zu Software wie DaVinci Resolve oder Adobe Premiere Pro für finale Bearbeitung zu exportieren. Dies umgeht Riversides Web-Editor-Einschränkungen
-
Zusammenfassend ist es ein "unschlagbares Aufnahme"-Tool, aber mit einem Editor, der noch versucht, die Reife dedizierter Software zu erreichen
Podsqueeze
Podsqueeze wird als KI-gestützte Podcast-Produktionsplattform präsentiert, die über einfache Audio-Behandlung hinausgeht. Es konzentriert sich auf komplette Workflow-Automatisierung von Klangverbesserung bis Content-Erstellung für Marketing und Social Media.
Was es gut macht: Wie Auphonic handhabt Podsqueeze intensives Hintergrundgeräusch, ausgeprägten Nachhall und Lautstärke-Ungleichgewichte sehr gut, solange die ursprüngliche Stimme treu ist. Dies umfasst Aufnahmen, die gemacht wurden mit:
- Normalen Mikrofonen
- Unvollkommenen häuslichen Umgebungen
- Audio, das vom Telefon erfasst wurde
Es ist besonders stark in Szenarien mit mehreren Sprechern und sorgt für konsistente und verständliche Lautstärken während der gesamten Episode. Dies funktioniert auch, wenn Aufnahmebedingungen zwischen Teilnehmern unterschiedlich sind.
Das verbesserte Audio bewahrt das menschliche Klangfarbe der Stimme, ohne auf aggressive Resynthese zurückzugreifen. Dies vermeidet metallische Artefakte, roboterhafte Stimmen oder "digitale" Effekte, die in anderen KI-Tools üblich sind.
Im Gegensatz zu isolierten Audio-Verbesserungstools ist Podsqueezes Audio-Verbesserer Teil eines Ökosystems, das speziell für Podcasting konzipiert ist. Es ist integriert mit:
- Transkriptionsfunktionen
- Textbasierter Bearbeitung
- Content-Wiederverwendung
Audio-Verbesserung ist vollautomatisch und produziert konsistente Ergebnisse zwischen Episoden. Es besteht keine Notwendigkeit, technische Parameter fein abzustimmen oder Audio-Engineering-Entscheidungen zu treffen.
Es erlaubt, Audio zu bearbeiten, indem Wörter direkt aus der Transkription entfernt werden. Dies ist ein enormer Zeitgewinn im Vergleich zu traditioneller Wellenform-Bearbeitung.
Es sticht hervor für seine Fähigkeit, automatisch kurze Clips für TikTok, Reels und YouTube Shorts aus langen Episoden zu generieren. Dies erleichtert Verteilung und Wiederverwendung von Podcast-Content.
Es bietet Multi-Show-Management und ermöglicht die Organisation mehrerer Podcasts in Ordnern mit spezifischen Einstellungen pro Show. Dies vereinfacht die Verwaltung mehrerer Shows oder Kunden.
Podsqueeze ist eine praktische und zuverlässige Lösung für Ersteller, die gute Ergebnisse ohne komplexe technische Workflows wollen.
Wo es Schwierigkeiten hat
-
Podsqueeze ist nicht für die Rekonstruktion stark degradierter oder komprimierter Stimmen indiziert. Beispiele sind Telefonanruf-Aufnahmen oder Audio mit schwerem spektralen Informationsverlust. In diesen Fällen können Stimmresynthese-Tools "dramatischere" Ergebnisse produzieren.
-
Der Fokus liegt auf dem Endergebnis und nicht auf manueller Feinabstimmung technischer Parameter. Dies kann Audio-Ingenieure einschränken, die chirurgische Kontrolle über jeden Verarbeitungsschritt suchen.
-
Obwohl der Audio-Verbesserer technisch solide ist, entsteht sein größter Wert, wenn er innerhalb des kompletten Podcast-Produktions- und Wiederverwendungs-Workflows verwendet wird.
-
Wenn du nur gelegentlich eine Audio-Datei verbessern musst, ohne Interesse an Transkription, Bearbeitung oder Wiederverwendung, können Tools, die ausschließlich auf Audio-Verbesserung ausgerichtet sind, eine einfachere und direktere Wahl sein.
Am besten für
Podcaster oder wiederkehrende Audio-Content-Ersteller, wenn:
- Die Aufnahme eine treue Stimme hat, auch mit Echo oder schwerem Hintergrundgeräusch
- Es Interviews mit mehreren Sprechern und inkonsistenten Lautstärken gibt
- Es Interesse an Wiederverwendung der Episode für Clips und Social Media gibt
Für Ersteller, deren Ziel nur ist, schnell eine isolierte Audio-Datei zu verbessern, können einfachere Lösungen, die sich ausschließlich auf Audio-Verbesserung konzentrieren, mehr Sinn machen.
Aber für Podcaster, die einen integrierten, konsistenten und effizienten Workflow suchen, sticht Podsqueeze als solide Lösung hervor, die gut auf seine Zielgruppe abgestimmt ist.
LALAL.AI
LALAL.AI wird weithin als Tool anerkannt, das mit der Spezialisierung auf Stem-Trennung (Aufteilen von Stimmen von Instrumenten) begann und sich zu einer kompletten Audio-Verarbeitungsplattform mit Rausch- und Echo-Entfernungskapazitäten entwickelte.
Was es gut macht: Es ist ein "wahnsinnig mächtiges" Tool zum Erstellen von Audio-Trennungen. Es ist fähig, Stimmen von Hintergrundmusik in Situationen zu isolieren, in denen andere Tools versagen.
Ich fand, dass LALAL.AI das iZotope RX-Paket (Industriestandard) übertreffen kann, wenn es mit "wirklich schwierigem" oder degradiertem Audio zu tun hat.
Es ist das Tool der Wahl, wenn du Dialog aus "gestohlenen" Materialien oder von externen Quellen mit urheberrechtlich geschützter Musik extrahieren musst.
Ich habe das Tool verwendet, um Musik aus Werbespots zu entfernen, die bereits in Stereo gemischt waren. Dies ermöglicht die Erstellung neuer Präsentationsmaterialien (Sizzle Reels) mit sauberen Stimmen.
Die Web-Benutzeroberfläche gilt als unkompliziert und einfach zu verwenden und ermöglicht Datei-Uploads und schnelle Ergebnisse ohne komplexe Konfigurationen.
Im Gegensatz zu starren monatlichen Abonnements bietet es ein Pay-as-you-go-Zahlungsmodell. Dies ist sehr attraktiv für Ersteller, die nur gelegentlich Audio bereinigen müssen.
Wo es Schwierigkeiten hat
-
Wenn das Tool zu hart arbeiten muss, um Rauschen oder Musik zu bereinigen, kann das finale Audio schrill, metallisch und übermäßig komprimiert werden.
-
Nach Musik-Entfernung bemerkte ich, dass ein subtiles Echo im Dialog verbleiben kann. Dies erfordert die Verwendung zusätzlicher Tools (wie Nachhall-Reduzierung in Premiere), um das Ergebnis zu polieren.
-
In meinen Tests schnitt LALAL.AI gelegentlich das Ende von Phrasen oder Wörtern, was Sprachflüssigkeit schadet.
-
Obwohl es Vorschauen erlaubt, erfordert das Herunterladen verarbeiteter Dateien die Zahlung von Minuten-Paketen.
-
Bei direkten Stimmbereinigungsvergleichen fällt LALAL.AI unter Auphonic in Bezug auf finale Qualität und Bewahrung natürlicher Stimme.
Am besten für
-
Editoren, die Dialog aus unmöglichen Situationen extrahieren müssen
-
Profis, die mit urheberrechtlich geschützter Musik arbeiten, die entfernt werden muss
-
Jeder, der Audio-Trennungsherausforderungen gegenübersteht, die andere Tools nicht handhaben können
-
Perfektion hat jedoch einen Preis. Du musst darauf vorbereitet sein, mit etwas Verlust an organischer Wiedergabetreue im Austausch für Stimmisolierung umzugehen, die wenige andere Tools erreichen können
-
Es ist nicht unbedingt die erste Wahl für tägliche Politur eines gut aufgenommenen Podcasts, aber es ist die "Geheimwaffe für unmögliche Rettungen"
Schnelle Empfehlungen nach Absicht
Die Wahl der besten Tools zur Audio-Verbesserung hängt von deinen spezifischen Bedürfnissen und deinem Workflow ab. Hier sind schnelle Empfehlungen basierend auf häufigen Szenarien:
Wähle AudioEnhancer.com, wenn: Du zuverlässige, natürlich klingende Audio-Bereinigung ohne technische Komplexität benötigst. Es ist perfekt, wenn Aufnahmebedingungen nicht ideal waren, aber die ursprüngliche Stimme treu ist, und du Studio-Qualitätsergebnisse schnell mit einem einfachen Upload-Verarbeitungs-Download-Workflow willst.
Wähle Adobe Podcast Enhance Speech, wenn: Du Aufnahmen aus schrecklichen Umgebungen retten musst, mit inkonsistenten Aufnahme-Setups arbeitest oder schnelle Verbesserungen ohne technisches Wissen willst. Es ist ideal für Notfallsituationen eher als primäre Produktionsmethoden, besonders für hochwertigen Content wie Hörbücher, wo KI-verarbeitetes Audio möglicherweise abgelehnt wird, weil es "nicht-menschlich" klingt.
Wähle Auphonic, wenn: Deine ursprüngliche Aufnahme bereits vernünftig ist und du professionellen, ehrlichen Klang willst, der natürliche Stimmdynamik bewahrt. Es ist perfekt für mehrere Sprecher, die konsistente Lautstärke benötigen, wöchentliche Episoden-Produzenten, die identische klangliche Signaturen wollen, und jeden, der Adobe Podcast zu künstlich findet.
Wähle Cleanvoice AI, wenn: Du verbale Tics, häufige Zögern oder prominente Mundgeräusche hast, die unmöglich manuell zu bearbeiten wären. Es ist ideal, wenn du synthetische/roboterhafte Klänge hasst und die ursprüngliche Textur deiner Stimme bevorzugst, akzeptierend, dass Hintergrundgeräusch möglicherweise nicht vollständig eliminiert wird.
Wähle Descript Studio Sound, wenn: Du Geschwindigkeit schätzt und die Plattform bereits für Multi-Kamera-Video-Bearbeitung oder Transkription verwendest. Sei vorsichtig, wenn du mit nicht-amerikanischen Akzenten arbeitest oder maximale akustische Wiedergabetreue benötigst, da es möglicherweise Natürlichkeit zugunsten absoluter Sauberkeit opfert.
Wähle DaVinci Resolve Voice Isolation, wenn: Du ein Video-Editor bist, der professionelle Audio-Bereinigung will, ohne deine Bearbeitungsumgebung zu verlassen. Es erfordert die Studio-Lizenz, bietet aber One-Knob-Einfachheit, die teurer dedizierte Software rivalisiert.
Wähle Krisp, wenn: Du Echtzeit-Rauschunterdrückung für Live-Anrufe, Streaming oder Remote-Arbeit benötigst. Verwende es mit Vorsicht für professionelle Aufnahmen, die maximale Wiedergabetreue erfordern, da es Stimmqualität verschlechtern kann.
Wähle Eleven Labs Voice Isolator, wenn: Du Audio retten musst, wo die Stimme so real und menschlich wie möglich klingen muss, ohne metallische Artefakte. Sei darauf vorbereitet, mit Lautstärke-Inkonsistenzen umzugehen und akzeptiere, dass Isolierung möglicherweise nicht 100% still in extremem Rauschen ist.
Wähle Riverside.fm, wenn: Du Remote-Interview-Podcasts produzierst, wo Bild- und Klangqualität Prioritäten sind. Viele Profis exportieren rohe Dateien zu dedizierten Editoren für finale Arbeit und verwenden Riverside hauptsächlich als Erfassungsstation.
Wähle Podsqueeze, wenn: Du ein wiederkehrender Podcaster bist, der einen integrierten Workflow mit Transkription, textbasierter Bearbeitung und Content-Wiederverwendung will. Es ist weniger ideal, wenn du nur gelegentlich isolierte Audio-Dateien verbessern musst.
Wähle LALAL.AI, wenn: Du Dialog aus unmöglichen Situationen extrahieren, urheberrechtlich geschützte Musik entfernen oder Audio-Trennungsherausforderungen gegenüberstehen musst, die andere Tools nicht handhaben können. Es ist deine "Geheimwaffe für unmögliche Rettungen", obwohl du möglicherweise etwas organische Wiedergabetreue opferst.
Fazit
Die besten Tools zur Audio-Verbesserung 2026 bieten unterschiedliche Ansätze zur Verbesserung der Klangqualität. Einige verwenden aggressive KI-Resynthese, um Audio von Grund auf neu aufzubauen. Andere konzentrieren sich auf konservative Verarbeitung, die ursprünglichen Charakter bewahrt. Einige glänzen bei spezifischen Aufgaben wie Rauschunterdrückung, während andere komplette Workflows bieten.
Der Schlüssel ist, das Tool an deine Bedürfnisse anzupassen. Wenn du mit stark beschädigtem Audio arbeitest, können Tools wie Adobe Podcast oder LALAL.AI Wunder vollbringen. Wenn du natürliche Politur ohne roboterhafte Artefakte willst, bieten Auphonic oder Podsqueeze besseres Gleichgewicht. Für Echtzeit-Szenarien führt Krisp. Für integrierte Video-Workflows glänzen DaVinci Resolve oder Riverside.fm.
Viele Profis verwenden mehrere Tools in ihrem Workflow und wenden jedes dort an, wo es am besten funktioniert. Der wichtigste Faktor ist nicht, das einzelne "beste" Tool zu finden, sondern zu verstehen, was jedes Tool gut macht und wann man es verwendet.
Beginne mit deinem größten Schmerzpunkt, teste einige Optionen mit deinen tatsächlichen Aufnahmen und baue dein Toolkit von dort aus auf.